作者丨郭 思
编辑丨陈彩娴

目前,开源大模型已经成为AI领域中的热门话题。
中信所报告近期指出,目前超过一半国内发布的大模型已经实现了开源,其中开源的主力是高校和科研机构,如清华大学的ChatGLM-68、复旦大学的MOSS以及百度的文心系列大模型。在这其中,自然语言处理是大模型研发最活跃的领域。
易于使用、开放性、高质量、免费是开源大模型现阶段备受追捧的显著特征。
开源一个7B或20B的大模型成为了不那么稀奇的事件,但技术发展行至深处,人们猛然发现,同质化竞争之下,开源大模型能否从空中楼阁变成实际的生产力,成为了赛事角逐的关键。
近日,在开源浪潮之下,上海人工智能实验室(上海AI实验室)推出图文混合创作大模型书生·浦语灵笔(InternLM-XComposer,以下简称“浦语灵笔”)。
目前,浦语灵笔已开源其中的智能创作和对话(InternLM-XComposer-7B)及多任务预训练(InternLM-XComposer-VL-7B)版本,并提供免费商用。
相比起市面上千篇一律的聊天助手,浦语灵笔另辟蹊径,没有选择拓宽做对话形式,而是转向了大语言模型的长文本能力以及图文多模态能力。现阶段,浦语灵笔能接受视觉和语言模态输入,不仅在图文对话方面表现优秀,更具备图文并茂文章的“一键生成”能力。
简而言之,搭载了浦语灵笔的应用,将会变得会写长文,也会根据文章内容进行插图,俨然一幅AI坐在工位上开始充当小编的模样。更为重要的是,这个小编是007工作制,可以24小时不用休息。
而当书生浦语灵笔团队打响开源大模型在实际应用的第一枪之后,几个值得思考的问题涌入了大众的脑海,开源大模型从技术到应用存在哪些壁垒?又该如何突破?面对同质化竞争,如浦语灵笔团队一般走出一条创新之路需要哪些要素?
1、当大模型学会文配图
人工智能写文章难吗?
其实也不难,只要输入关键词,提出需求,绝大多数的产品都能丢出一份500字的小作文。
但是一旦将需求改成1000字或者2000字,大部分产品都会显示无法执行。
现在主流的大语言模型大都只支持短文本的输入(LLaMa支持2k tokens、Llama2支持4k tokens)。
而日常生活中,长文其实会更加严肃,也更符合工作需求。
只是不断趋近于人类的大模型也有人类普遍拥有的「懒」病。
早在今年6月份斯坦福大学、加州大学伯克利分校和 Samaya AI 的研究者发布了一篇实证研究论文,深入探讨了大模型的懒病问题,如果上下文过长,LLM会更多地关注起始和末尾部分,而几乎忽略中间部分的信息。这种现象导致模型难以找到并利用放在长文中部的相关信息。
大众苦大模型长文本能力久矣。
长文本能力也是各家发力的重点,10月,杨植麟创业AI公司月之暗面(Moonshot AI)推出了首款大模型产品智能助手Kimi Chat,主打的就是,千亿参数大模型,支持输入的长文本首次达20万x字。香港中文大学贾佳亚团队联合MIT近期也宣布了一项新研究,发布全球首个70B参数的长文本开源大语言模型——LongAlpaca。
从今年7月起,上海AI实验室便陆续开源了书生·浦语大语言模型的7B(InterLM-7B)及20B(InternLM-20B)版本。
模型参数虽然没有那么大,但是书生浦语20B(InternLM-20B)版本硬是凭着先进的性能以及应用的便捷性达到了当前被视为开源模型标杆的Llama2-70B的能力水平。
现阶段书生·浦语——InternLM-20B最高支持16k语境长度,对长文本理解能力更强。InternLM-20B 在超过 2.3T Tokens 、包含高质量英文、中文和代码的数据上进行预训练。
基于书生·浦语大语言模型(InternLM),浦语灵笔也有强大的长文理解能力。
如果说长文本能力是大模型写作各家追逐的一个卡点,那么如何让AI更好的像人一样掌握全流程工作技能,便是模拟一个真正的工种的关键。
信息化时代,一篇成品的文章,很少会只有一段文字。
无图无真相,是大众对信息传播新的要求与期待。
普遍的写文需求是,当写完了一篇长文之后,人们往往需要判断,在哪个地方需要插图。
对人而言,这很简单,但是对大模型而言,这意味很高的要求。为这个任务足够主观,同样一篇文章交给不同的编辑会有不同的呈现效果。
怎样让大模型去理解这个任务呢,其实这便要求书生浦语灵笔有强大的图文多模态理解能力。
首先,这需要大模型对文章的内容有一个很好的理解。也需要对整个候选图库里面几千万张图有很好的认识。比如涉及最近热门的科学养宠的话题,大模型需要根据文章类别判断,整篇文章是需要宠物的图片还是狗粮的图片。
另一方面,大模型也需要对整体文章风格有充分的认识。一篇轻松欢快的文章最好能配上明亮、快乐的照片,如果讨论的话题比较沉重,就应该偏严肃,带灰调。
按照这个理解,这就要求在在技术实现上,大模型必须实现像人类一样多步思考,把握全局的能力。
为了实现这一点,浦语灵笔采用了多阶段的训练策略,在大规模的图文数据集上进行多模态预训练,学习图文之间的关联和对齐,然后在多个具体的任务数据集上进行多任务训练,提升模型在各个任务上的性能。
预训练和多任务训练的过程中,浦语灵笔使用了多种自定义的损失函数和评价指标,以适应不同的任务需求。
灵笔的「三步走」的算法流程也正是模拟人类进行工作的多阶段细化。
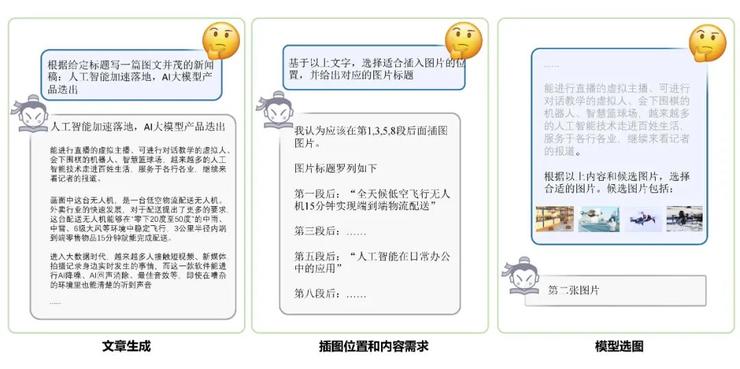
浦语灵笔图文文章创作流程
浦语灵笔会先去理解用户指令,创作符合主题要求的长文章,然后会进行智能分析文章,模型自动规划插图的理想位置,并生成所需图像的内容要求。
进行完这两步之后,如果人类作为一个监工去审查大模型的工作,我们会发现结果可能还是不够理想,有可能模型规划的位置不对,也可能选取的图像与描述不相符合。
浦语灵笔团队在进行构思时,也考虑到了这一可能,多层次智能筛选,便是浦语灵笔能做到的第三步,也是极为关键的一步。
利用多模态大模型强大的图像理解能力,浦语灵笔会从图库粗选出来4张或者 8 张候选图,之后模型会根据文章上下文,基于对图像内容的精细理解,从所有的候选图里挑选一张他认为最合适的,完成选图过程。
在这一步,浦语灵笔的图文混合创作能力得以完美体现,而这个能力的先决条件便是得先有图文理解能力。现有的 NLP 模型能理解文字,但是无法做到理解图像,这是浦语灵笔与市面上其他语言大模型最核心的区别之一。
现阶段,灵笔的图像理解能力在多个多模态大模型的评测上都达到了最高的性能。
足够智能的底层其实是十分扎实与卓越的基础能力。
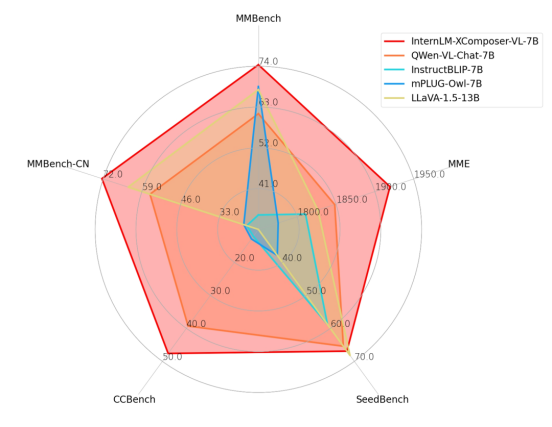
浦语灵笔与其他开源模型的性能对比
2、开源大模型走向应用需要几步走?
大模型落地的产品形态同质化已经成为了中国市场的无形枷锁。
这件事情在没有大模型开源模式还没出现之前是如此,在大模型陆续开源之后也是如此。
将ChatGPT单词拆分,绝大多数都关注到了Chat,于是对话式产品层出不穷。百模大战,100个产品里有90个都是对话形式。
AI产品仿佛陷入了一个魔咒,一边是热络的行业氛围和资本市场,一边是大量AI产品以同质化、雷同化的形象出现在市场上。
其实这也折射出新兴技术转化为生产力的必经历程。
顶层的设计往往充满着不确定性,而市场的判断却是朴素而直接的:谁能给我带来收益和更多的价值,谁就是对于我有用的。
所以产业界才会一窝蜂的追寻噱头与热点。市面也才会出现那么多大大小小的聊天机器人。
而我们回归问题本身,会发现产品同质化是表现,随波逐流的思维定式本身才是疾病。
正如ChatGPT出现时,大家最先关注的只是Chat一样,如果只围着一种形式发展与思考,出来的东西必然没有创新的灵魂。
但如果关注ChatGPT的内核,便可以发现大模型体现出来的是更强的泛化性能力,能够在更多领域带来通用的智能化变革。大模型带来的革命最终还是要回归到技术本身的价值,要应用和落地,不会永远的只是一个聊天的Demo。
开源大模型走向应用的第一步先得从思维上打破定式。
在进行大模型开源的时候,我们如何看待大模型?
众所周知,大语言模型的基本原理是仿生——用“数学参数”模拟人脑的“神经元突触”,当参数超过1000亿个,就可以认为它是“大”模型了。
普遍的认知是,参数够大便是大语言模型。
但如果重读大语言模型的基本原理,会发现,模拟人脑也是大语言模型的一个显著特征。
而在上海人工智能实验室领军科学家林达华看来,如果把大语言模型看成是某一个模态对世界的理解与感知的模型,就会相当局限,看待大语言模型,我们应该将它理解成为一个中枢的大脑,可以调用各种工具,跟这个世界发生各种各样的交互。
比如说跟一个机器人结合,让机器人从原来只有小脑变成多了一个大脑,能干很多很丰富的事情。也可以和具体的提供服务的网站去结合,电商也好,购物也好,用户可以对跟网站进行交互,从一个简单的检索变成了更丰富的获取信息的方式等等。
浦语灵笔的构想最开始来自于团队成员的真实需求。
书生浦语灵笔的团队负责人王佳琦在一次使用ChatGPT之时,发现自己大多时候都只想用ChatGPT来创造文本。
「要是生成完文章之后,可以直接配图就好。」
借由这个思考,上海人工智能实验室从4月开始便着手构建了书生·浦语灵笔的项目。
而在打破思维定式之后,开源大模型走向应用还得在技术设计上「立」得住。
众所周知,开源为技术创新提供了广阔的舞台。通过开源,企业可以共享自身研发的技术成果,促进技术的交流和融合。因为只有来自底层使用者的心声,才是进行技术改进最好的源动力。
Github、阿里的魔搭、百度文心一言的AI Studio星河大模型社区,都是想在活跃的社区氛围中探索商业变现的渠道。
此前在世界互联网大会数字文明尼山对话上,百度创始人李彦宏就曾曾指出“新的国际竞争战略关键点,不是一个国家有多少个大模型,而是你的大模型上有多少原生的AI应用,这些应用在多大程度上提升了生产效率”。显然,开源大模型要想立住自己的核心竞争力,开发者社群是一个非常关键的要素。
在与AI科技评论的交流中,浦语灵笔团队反复多次提到“用户说”“社群反馈”这样的字样,然后解释浦语灵笔后阶段会如何根据这些信息进行性能上的提升。
从这一点上而言,当一个研究团队没有闭门造车,而是不断地与产业界交流,思考自己的方向的改进,看似很理所当然,却又是十分影响成败的关键细节。
现阶段,浦语灵笔的角色定位十分清晰,产生的影响也十分明显。
「灵笔做好之后,确实能够成为有效的生产力工具,能够让大家去进行一个很好的文字图文创作工具,有一个小编他可能要写一个知乎专栏,或者要写微信公众号,需要这种图文交错的创作情况下,灵笔能做得很好。我们的角色相当于是给大家去做示范,这个事情是可行的。」
原子弹最有用的价值,是他能被造出来。
书生浦语灵笔的开源,也同样为了让整个行业有多一点点的思考。
究竟自己在整个浪潮中处于怎么样的定位,如何走出自己的路?
思考清楚了,开源大模型从技术走向应用或许也就不远了。
(本文作者郭思 微信号:lionceau2046,长期关注大模型领域前沿技术与产品,欢迎大家共同交流,互通有无。)
雷峰网 雷峰网(公众号:雷峰网) 雷峰网






发表评论 取消回复