雷锋网AI研习社按:DAC19目标检测设计是一个面向移动端的单目标物体检测的比赛,检测精度高且能耗低者胜出。我们团队设计了单目标检测的深度学习算法ShuffleDet,和面向Xilinx ZU3的AI硬件加速器,获得了FPGA赛道的第二名。本次分享主要介绍我们团队的设计方案。
分享嘉宾:赵文哲,西安交通大学人工智能与机器人研究所研究员,伦斯勒理工学院访问学者,主要研究方向为计算机体系结构,纠错码设计,以及企业级存储方案设计。
公开课链接:http://www.mooc.ai/open/course/674?=from%20leifeng0717
分享主题:HiPU设计简介--DAC19目标检测设计竞赛FPGA赛道亚军方案介绍
分享提纲:
DAC19比赛背景介绍;
算法选择及训练介绍;
一种通用目的的AI加速器设计简介;
性能分析与结论。
雷锋网AI研习社将其分享内容整理如下:
大家好,我们来自于西安交通大学人工智能研究所。在今年DAC会议举办的自动化系统设计大赛上获得了亚军,今天主要介绍一下我们的设计方案。我负责这个方案的算法部分,算法部分主要进行了目标检测递层框架的搭建、神经网络算法的压缩,后面主要由赵老师讲一下硬件架构的设计。

这个是由英伟达、大疆他们共同组建的一个比赛,数据集由大疆提供——基于大疆无人机拍摄出的目标检测的数据集,比赛从准确率、速率、网络效率等方面综合考量之后,给参赛队伍一个相应的分数,以上这些是关于比赛的大概介绍。

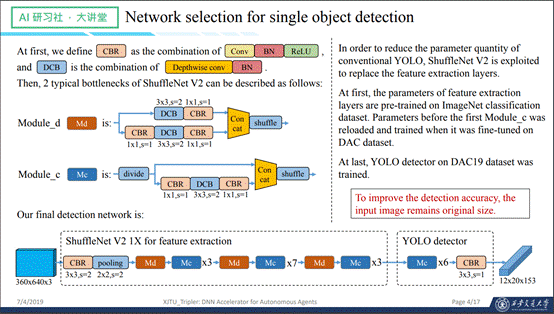
在比赛中,算法方面主要是两个工作,第一个是神经网络的选取,这个工作需要在一非常小的BP上配置神经网络,所以首选储存空间小、效率高的这种来作为特征提取的基本网络。在这个网络训练过程中,主要进行了两个部分的优化,首先是将神经网络进行预训练,第二个优化是针对硬件优化的,将ShuffleNet V2变成8的倍数,方便后面进行配置。
算法方面的第二个工作主要是介绍网络的量化,网络的量化也分为两个主要的部分,首先是将一些特殊的层进行融合,如图示左边部分。其次是8bit的量化过程,如图示右边部分。
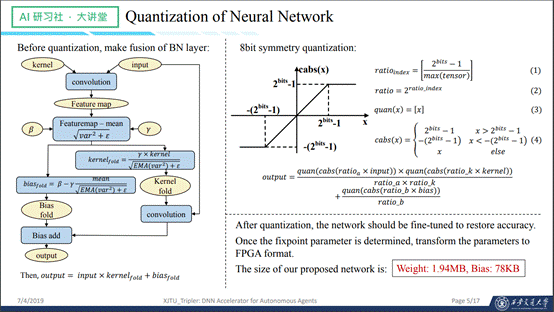
下面介绍一下量化过程中的一些关键点,第一个点就是神经网络越小,量化难度越高,来看一下下图所示右边部分,是当时我们为了验证这个说法做的一个实验。第二个点就是上一页的cabs函数,这个函数主要是保护权重和输出在要求的范围内不产生溢出,最好是先让网络训练一段时间,在权重和输出都比较稳定的时候再把函数加入进去。第三个点就是ratio_a,指的是输出值,这个值的统计是一个非常精细的过程。第四个需要注意的点就是,在完成离线的量化工作之后,在实际操作中,需要跳过round函数的梯度。
关于量化这个领域,建议大家读一下以下这些论文,如下图。

我这部分讲完了,接下来是赵老师来介绍。
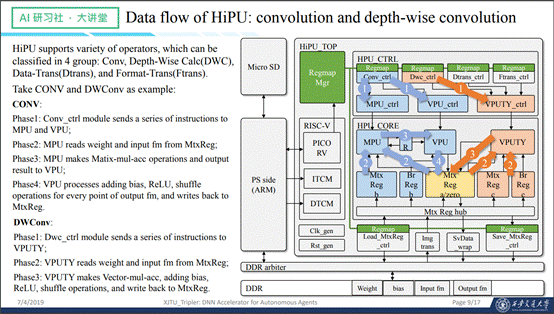
在我们的网络和参数训练完成之后,就需要设计一套硬件加速处理器,以便让神经网络能够高效的运行。为了实现上述目标,我们设计了一个通用的,可以支持几乎所有网络的加速器,将它命名为HiPU。这个加速器主要包括这样几个模块,首先是一般的控制模块,除此之外有矩阵运算和矢量运算。在HiPU里面,主要是处理卷积、Depth-wise卷积、padding、pooling、跟channel相关的shuffle操作以及concat操作。
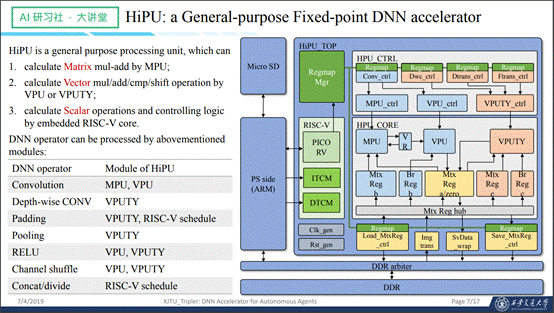
先看一下几个基本操作,如下图右侧所示,是HiPU的基本结构图。
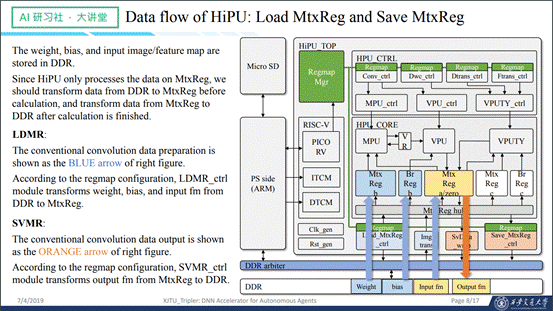
接下来看一下计算过程,以卷积为例,当数据已经放在MRa、MRb中之后,通过计算器发出开始卷积的命令,然后conv_ctrl模块会把一个卷积拆解成很多矩阵运算和矢量运算的指令,MPU和VPU内部会把数据读上来,计算完之后再送到VPU做一次运算的结尾部分,算完之后再写回到MRa之中,流程大概就是这样。DW卷积也是类似,如图所示。
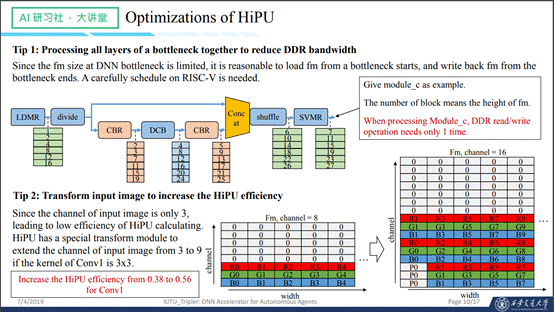
接下来看一下相关的几个优化,首先我们并不是算完一层就立刻返回,以module_c为例,先做一个切分,把前一半的数据直接传到后面,后一半的数据分别经过1x1的卷积,然后经过3x3的卷积,再经过1x1的卷积,和之前的数据做一个shuffle之后输出。在这个过程中,并不是说做一个卷积就算完了就立刻输出。继续讲第二个优化,在此之前说一下我们这种做法的问题,问题是一次需要读入8个输入channel的数据,但是输入层只有RGB三个通路,如果要处理这样的数据,就必须要补上5个channel的0,计算效率也就只有八分之三。针对这个问题,如果第一层卷积是3x3的,可以考虑做这样一个变换,把相关的数据排列过来,如下图,这样的做法可以让卷积效率提高很多。
除此之外我们再看一下作为系统的优化,系统分为PS侧和PL侧,大部分卷积运算都是放在PL侧进行的,最后一层的输出是放在PS侧来做的。在PL侧做大量卷积运算的时候,PS侧是空闲着的,但是现在在做当前图的卷积运算的时候,PS侧会进行下一张图的预读取,通过这种方式可以显著地减少读图所消耗的时间。除此之外是对计算Calc bbox的优化,通过外扩C函数,把计算时间从2毫秒降到0.6毫秒,而且,读图像的时间也可以减少。最后还有一个问题,之前使用的SD卡并不是最好的SD卡,会出现这种PS侧一直在读图,但是PL侧已经算完了的尴尬情况,于是增加了一个门控时钟来降低功耗。

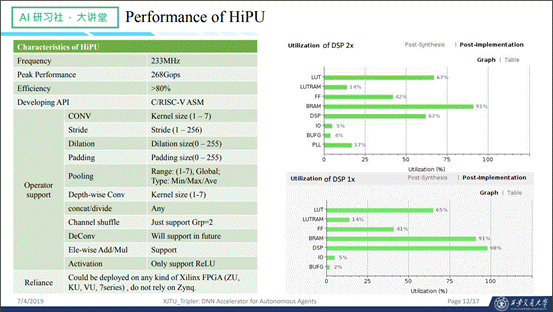
接下来是HiPU的一个总结。我们的HiPU可以在单倍频和双倍频模式下工作在233MHz,峰值算力为268Gops。资源占比中,LUT站到62%左右,还有继续提升的空间。编程API为C以及RISC-V风格的汇编。支持的主要操作如下图所示:
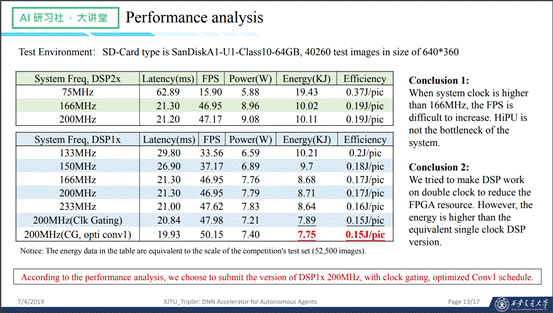
下图是HiPU在不同的配置环境下执行这次比赛的任务的性能分析:
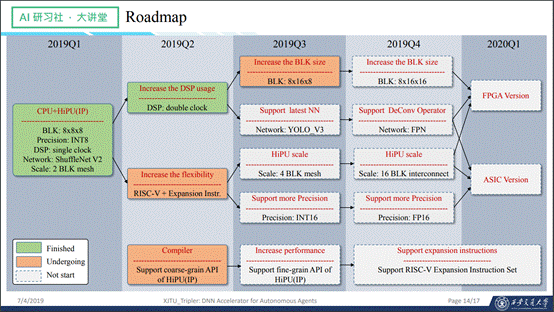
介绍一下我们的Roadmap,如图所示:
最后请欣赏我们设计的2个Demo:

今天的介绍主要就是这些,谢谢大家。
以上就是本期嘉宾的全部分享内容。更多公开课视频请到雷锋网(公众号:雷锋网) AI 研习社社区http://ai.yanxishe.com/观看。关注微信公众号:AI 研习社(okweiwu),可获取最新公开课直播时间预告。






发表评论 取消回复