12月12日,中国权威的大模型评测平台OpenCompass日前更新了榜单,阿里云通义千问登上开源基座大模型榜首,并在中文数据集评测中包揽前二。
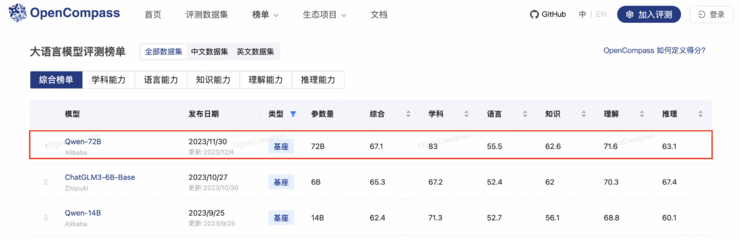 图说:通义千问72B登顶OpenCompass基座大模型榜
图说:通义千问72B登顶OpenCompass基座大模型榜
OpenCompass是上海人工智能实验室开源的大模型评测平台,涵盖学科、语言、知识、理解、推理等五大评测维度,支持50余个数据集的评测,Qwen、LLaMA2等开源模型及GPT-4、ChatGPT等主流模型均参与评测,可全面评估大模型能力,是业界公认最权威的中文能力评测榜单之一。
通义千问72B开源模型(Qwen-72B),以67.1的综合得分夺得OpenCompass基座大模型榜单冠军,并在学科能力、理解能力两大维度评测中超越标杆GPT-4,创下开源大模型的新纪录。而在OpenCompass中文数据集评测中,通义千问72B基座大模型和对话大模型(Qwen-72B-Chat)包揽前二,与其他模型拉开差距。
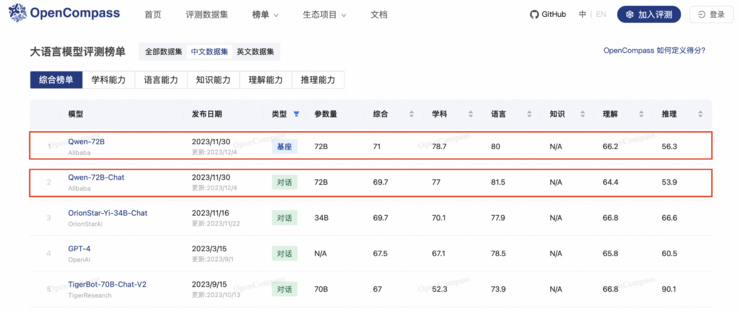 图说:通义千问72B基座大模型及对话大模型包揽中文数据集测试前二
图说:通义千问72B基座大模型及对话大模型包揽中文数据集测试前二
据了解,自12月1日开源,通义千问72B即在10个权威基准评测中创下开源模型最优成绩,几天前力压Llama2登顶全球最具权威性的HuggingFace排行榜,此次又登上OpenCompass榜首,通义千问72B已成为国内外公认的性能最强的开源大模型,完全可满足企业级、科研级应用对大模型性能的高要求。
截至目前,阿里云已开源通义千问18亿、70亿、140亿、720亿参数的4款大语言模型,以及视觉理解Qwen-VL、音频理解Qwen-Audio的 2款多模态大模型,开源模型系列总下载量超150万,并涌现出150余款新模型和新应用。
为打造“AI时代最开放的大模型”,通义千问将持续投入开源,并为中小企业及全球开发者提供更便利的大模型服务:开发者可在阿里云魔搭社区直接体验系列模型效果,也可通过阿里云灵积平台调用模型API,或基于阿里云百炼平台定制大模型应用;阿里云人工智能平台PAI还针对通义千问全系列模型进行深度适配,推出轻量级微调、全参数微调、分布式训练、离线推理验证、在线服务部署等服务。
雷峰网(公众号:雷峰网)






发表评论 取消回复