
作者 | 王金旺
出品 | 雷锋网产业组
雷锋网消息,5月17日,搜狗CEO王小川在搜狐科技5G&AI峰会对外发布了新一代搜狗AI合成主播——手语AI合成主播“小聪”。
作为搜狗AI合成主播经过两年多时间迭代后的新品,手语AI合成主播集成了超写实3D数字人建模、机器翻译、多模态数字人生成、迁移学习、实时面部动作生成及驱动技术。据搜狗官方信息显示,在组织的聋人可懂度测评中,搜狗手语AI合成主播可懂度达到了85%以上。
搜狗这款手语AI合成主播研发初衷是什么?
为什么有了语音识别生成字幕技术后,还要做搜狗手语AI合成主播?
搜狗手语AI合成主播与一脉相承的语音识别、AI分身在技术研发过程中又有何异同?
……
这些问题都在5月19日的媒体沟通会上由搜狗AI交互技术部总经理陈伟及他的团队进行了一一解答。
研发初衷:听障人士看字幕如学外语般艰辛
2018年11月,搜狗与新华社合作研发的AI合成主播正式问世,几经迭代后,在2020年5月,又与新华社联合推出了3D AI合成主播。
当时陈伟和他的团队在为搜狗为3D AI合成主播规划未来发展方向时,着重考虑了三个方面:
第一,要把3D能力做好;
第二,我们希望搜狗在“数字人”这个方向上有自己更高的技术壁垒;
第三,我们要找到有强烈需求的场景。
综合考虑场景、渠道和技术迭代中的创新后,2020年5月,手语AI合成主播在搜狗内部正式立项。
既然有字幕了,还要手语干什么?
这也是搜狗手语AI合成主播立项之初,陈伟当时需要考虑的问题。
对此,陈伟总结了三方面原因:
第一,并非所有听障人士能看懂字幕。
在我国2700万听障人士中,整体受教育程度参差不齐,有高中、大学学历的听障人士在这一群体中仍然只占非常小的比例,现在大家对字幕获取的能力还在逐渐培养中,要想让绝大部分听障人士看懂字幕还有很长的路要走。
第二,「有字幕」这件事儿和「做手语」不是必须二选一的。
我们在了解信息、获取信息过程中必然会通过多种方式,我们自己在看电影的时候,有时候尽管中文的电影我们可能也会看字幕,大家本能的想法是我怎么能更快更高效的获取信息,他能看懂字幕更好,如果看不懂,还有手语可以提供信息。
第三,手语语言和有声语言之间是完全不同的语言体系,听障人士对有声语言的接受程度类似健听人对第二外语的接受程度。
听障人士即便学习了汉语,对他来说也是第二语言,就像我们在学习英语过程中,尽管我们学习了很长时间,但还是很难产生熟悉的感觉。
与此同时,听障人士在学习汉语的过程中其实天生是有障碍的,因为汉语或者普通话更多的是表音文字,每个字都有发音,我们之所以能够快速学习语音,是因为有语境。我们跟别人沟通的时候,沟通的前提是眼睛看着大家,看到了唇形,同时听到了声音,结合在一起是多模态的,但是听障人士在听力上天生有障碍,就少了一个因素让他更快地学习有声语言。他们之所以学手语学得快,是因为手语是视觉语言,不需要辅以声音进行理解。从这个角度来看,手语短期内不可能完全被字幕替换掉,它仍然是听障人士的主要学习方式,手语表达也更符合听障人士的习惯。
就在搜狗手语AI合成主播发布的同时,搜狗还对外发布了柳岩同款明星“数字人”。

据陈伟透露,柳岩同款明星“数字人”从录制到上线用了有一个月的时间,其中录制仅用了两个半天(合计一天),数据标注花了30%-40%的时间,剩下的则是技术研发和迭代用的时间。
而手语AI合成主播“小聪”的技术难度要远远大于明星“数字人”。
研发历路:手语是门“视觉语言”
搜狗研发了多代AI合成主播,在语音识别技术上也积累颇丰。然而,手语AI合成主播对于搜狗而言,仍是一个全新的领域。
据陈伟介绍,搜狗在做手语AI合成主播“小聪”时,主要做了三方面工作:
「语言侧手语的研究」、「语言体系的翻译」和「表征表达」。
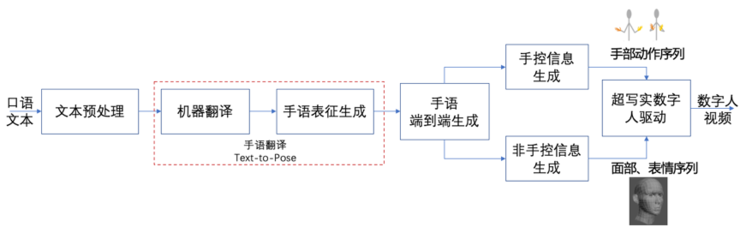
首先,在研发“小聪”过程中,搜狗最先遇到的就是手语数据库建立的问题。
搜狗开始接触手语发现了一个问题:手语语言和所有其他(有声)语言都不一样,它是一个视觉语言。
随之而来的一个问题是:“小聪”的训练数据从何而来?
陈伟解释称,手语语言如何转换成计算机语言,之前行业在做手语语言体系时并没有特别明确的做法,要么是纯语言学,要么是计算机相关背景的人根据自己的想象做手语。
在搜狗团队的认知中,手语本身是没有可记录的文字信息的,因为它本身就是视觉信息。
《国家通用手语词典》一共8000多个词,“小聪”基于《国家通用手语词典》进行健听人语言与听障者手语语言的机器翻译,在这个过程中,为了构建用于模型训练的数据库,搜狗做了三方面工作:
第一,从语序到选词,我们会考虑把健听人的语言和听障人士的语言做一个平行的翻译,这样就可以积累大量的资源,用这样的资源作为翻译系统的数据;
第一,将手语词汇转化成用文字方式或用技术方式标注出来;
第二,构建健听人和听障人士之间语序的平行翻译语料,这需要大量的机器翻译库;
第三,通过预先捕捉大量真人动作和表情数据,对构建起的3D模型进行模型训练,因为搜狗走的是超写实模型,这件事情每个环节都有很大的资源和研发投入。
据陈伟透露,从翻译角度来讲,现在初步建立起来的精标数据达到几万。
其次,搜狗要考虑的第二个问题是——语言体系如何构建。
手语和汉语本质上不是一个语言体系,存在着诸多结构、表达上的差异。在这之中,“小聪”研发团队特别提到三个难点:
第一,手语表达与汉语表达语序的不同。例如,汉语中的“开车不许喝酒”,手语表达出的则是“开车、喝酒、不准”,包括像“北京常常堵车”会被翻译成“北京、堵车、常常”。
为此,搜狗建立了相应的语言规则尝试做相应的语序转化,通过搜狗构建数据库给算法进行训练。
第二,在词汇上,手语中没有虚词和量词。“我买两只铅笔、一本书”,手语表达出来的会是“我买铅笔、二、书、一”;包括“在、的、了”等程度词都会省略,“大雪纷飞”用手语表达也不会有一个词表达“大”、一个词表达“雪”,而是在“雪”的基础上加大身体的摆动来体现程度副词。
为此,搜狗建立了手语到汉语之间的映射辞典,尝试去解决手语和汉语之间词汇上的差异问题。
第三,手语里特有的非手控的信息,例如表情、口动、身体的朝向,这部分是在汉语语言中所没有的。例如同一个手势表达“我做的好不好”,如果没有表情的话,大家很难明白手语表达出来的意思,但是如果有皱眉,就是能表达出疑问的语气。
表情、身体姿态、口动等非手控信息是搜狗在做“小聪时”遇到最大的难题,目前也在尝试通过一些建立一些表情库或存在表情标记的数据库驱动算法的设计等规则的方式来解决这一问题。
最后,搜狗还需要用这样的语言体系驱动“数字人”“小聪”完成自然连贯的手语动作、面部表情表达。
“手语翻译是一个新的话题”
这个事情的难点是我们一帮不懂手语的工程师在做事情,特别容易陷入到自己的烟囱里面。
陈伟一语道破研发团队立项初期的窘境。
在进行过深入研究后,陈伟发现,手语翻译是一个新的话题。
我们同传上线了这么多年,原来做的中英翻译、中日翻译等结构都是一样的,但是放在手语上又不一样了,它有一些新的话题。
为此,陈伟请来了制定手语标准的残联及相关协会专家、教手语的手语老师、做手语推广的专业人士,由这些人组成了搜狗手语AI合成主播语言体系、产品体系、研发体系之外的智囊团作为顾问团队。
从立项之初,搜狗就一直与这一顾问团队保持着紧密联系,这也成为搜狗手语AI合成主播在技术迭代过程中不至于偏离最终用户的一个保障。
“数字人”的一个终极目标是手、嘴、表情、姿态的实时联动,完美复刻真人表达能力,这也正是手语对表达能力的需求。
据搜狗官方信息显示,“小聪”在测评中可懂度已经可以达到85%以上,能够进行有效信息传递。
对此,陈伟也向雷锋网解释:
可懂度85%,跟(语音)识别准确率98%是两个概念。识别率是客观指标,这个字到底对还是错的问题;可懂度更强调听障人士的体验,我在表达的时候,翻译得准,“数字人”表达得准,这个链条太长了,在这件事上每个环节都得做好,串联起来才会得到一个比较满意的效果。
与此同时,陈伟也指出:
数据量足够的话,提升读懂度在技术上不是特别大的问题,不过,数据资源的积累需要比较长的时间成本,我们在快速推进,但还是需要有时间积累。



发表评论 取消回复