
作者 | 王德清
出品 | 雷锋网产业组
当前,对于每一个企业的数字化转型和可持续发展来说,数据起到了至关重要的作用。
“一切业务数据化,一切数据业务化”,也成为当今诸多企业的口头禅。
据知名咨询机构统计,到2025年全球数据总量将超过160ZB,全球数据总量的近 20% 将成为影响日常生活的关键数据,近 10% 将变为超关键数据。
随之而来的就是,企业对于数据洞察敏捷度要求的不断提升,同时企业也迫切需要可以利用多个数据源、使用不同的大数据分析技术,快速构建灵活友好的数据架构,解决多元化分析场景的数据需求。
基于这一洞察,日前,腾讯云首次对外展示完整云端数据湖产品图谱,并推出两款“开箱即用”数据湖产品——数据湖计算服务DLC和数据湖构建DLF。
云原生智能数据湖到底具有了哪些能力?可为企业带来哪些价值?为了探讨这些问题的答案,会后,雷锋网与腾讯云大数据产品中心副总经理雷小平、腾讯云容器产品总经理邹辉、腾讯云AI应用产品中心总经理王磊进行了一场对话。
云原生智能数据湖带来了哪些不同?
众所周知,数据湖并非是一个新的概念,早在2010年,Pentaho创始人兼CTO詹姆斯·狄克逊(James Dixon)就提出数据湖概念,同期Pentaho发布了开源框架的Hadoop第一版。
随后,蓝色巨人IBM、EMC等也推出了数据湖解决方案,其核心基于分布式文件系统建立的数据存储方式,横向扩展比较强大,实现了集中统一管理。与此同时,基于HDFS系统带来的Hadoop和Spark开源生态构建,也在一定程度上推进了企业数据湖的进程。
但受限于开源软件本身能力的限制,传统数据湖技术无法满足企业用户在数据规模、存储成本、查询性能以及弹性计算架构升级等方面的需求,无法达到数据湖架构的理想目标。

在雷小平看来,传统的数据湖产品只是解决了大数据“存”的问题,在“用”的维度上并没有产生更大的价值。
而伴随着数字化时代的到来,企业用户对于大数据产品有了更高的要求,需要更低廉的数据存储成本、更精细的数据资产管理、可共享的数据湖元数据、更实时的数据更新频率以及更强大的数据接入工具。
这直接导致了传统数据湖产品难以深入企业级行业用户。
面对着企业对于大数据工具需求的全面变化,以及以云计算为中心、以数据驱动业务及可组合式数据架构成为数智时代的数据分析的趋势下,云原生智能数据湖应势而生。
“云原生智能数据湖,能够很好的扩展计算和存储资源,同时能极大地降低运维管理难度,实现业务灵活部署。同时可以助力各行各业解决多元化数据分析场景的新需求,更好地激发大数据在企业数字化升级过程中的价值。”雷小平接着对雷锋网表示到。
“相比过去的数据湖,云原生数据湖的优势主要体现在能够以极低的价格共享存储服务;计算资源能够按需扩容,按量付费;同时随着数据湖全链路解决方案的不断完善和增强,也在打破数据孤岛、实现多元化数据分析等方面具有独特优势。”
基于对行业的这一理解,在雷小平看来,企业需要一个具备端到端的云原生数据湖解决方案,从存储、计算到智能的数据分析,再到偏向业务场景的各种数据应用,通过“从下到上”的把这些能力聚合在一起,同时结合数据湖的能力去解决业务中的具体问题,并能够快速搭建并运用数据湖的技术架构。
云原生智能数据湖带来了哪些价值?
随着技术的不断演进,数据库技术正在与云计算以及人工智能技术相融合,结合云计算以及人工智能的特性,云数据库正呈现出更高的数据敏捷度、更优的数据存储分析成本,以及更极致的资源弹性能力,在打破数据孤岛、实现多元化数据分析等方面具有独特优势。
就以腾讯云原生智能数据湖为例,其产品矩阵包括数据湖存储、数据湖算力调度、数据湖大数据分析、数据湖AI能力、以及数据湖应用和云上基础服务六个层面,提供一体化的全方位服务。
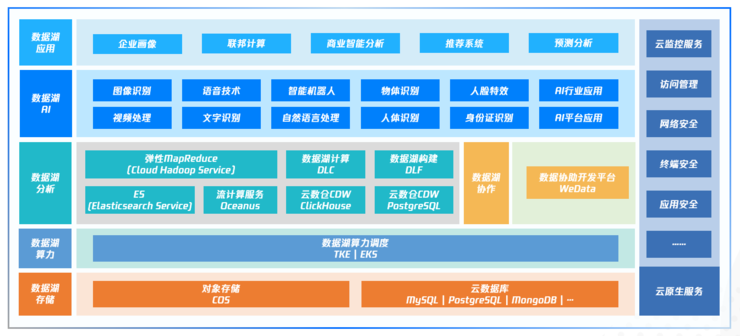
在存储方面,腾讯云原生数据湖存储以对象存储COS服务为核心,理论上可以存储任意规模的异构数据,具有高可靠性和高持久性,同时也支持将其他云端数据设施作为数据湖的存储服务。
对于腾讯云对象存储,雷锋网曾在《腾讯存储技术背后的十五年往事》一文中进行详细描写过,腾讯云对象存储COS基于新一代存储引擎YottaStore打造,不仅具有高可用、高性能和低成本等优势,且在存储可靠性、开放兼容和数据安全方面也为海量数据的存储和管理提供了更强大的支持。此外,腾讯云对象存储COS还进一步通过“三级加速器”,提供存储端元数据、近计算端数据缓存以及AZ级全闪存硬件加速能力,可以满足用户低成本、高性能、流批一体地挖掘数据资产价值的需求。
在算力调度方面,腾讯云弹性容器服务EKS,具备存算分离、缓存加速、弹性计算能力,既能帮助企业充分利用云上资源的弹性能力,极大减少集群空闲时期的成本浪费,也能快速、安全的提供多样的算力资源。
据邹辉介绍,弹性容器服务EKS不仅经历了三次大的技术架构重构,同时也在腾讯云几十万、几百万台的物理机上做了部署,实践验证了其高可用和稳定性,它既可以提供一个运维简单、兼容原生Kubernetes的Serverless容器平台,也能更快更弹性更安全且无需对集群管理实现管理,同时更具备跨可用区的容灾,容器沙箱及热迁移等高级功能,真正实现了极致的资源使用灵活性。
同时,面向企业的混合云部署场景,腾讯云的EKS可以在用户的机房中部署一个插件,当客户需要更多算力资源的时候,通过这一个插件就可以使用腾讯云提供的性容器服务EKS服务。
其次,在数据湖分析方面,腾讯云原生数据湖同样既提供半托管的泛Hadoop服务,满足用户自定义需求,也提供全托管的数据服务,便于用户获取海量数据的洞察力。同时,用户还可利用腾讯云提供的数据协作工具对计算服务进行编排和调用,大幅度提升企业数据的便捷性和敏捷度。
在数据湖智能应用方面应用方面,腾讯云推出了基于数据湖的数据应用服务,如企业画像、联邦计算、商业智能分析等。同时,腾讯云数据湖更包含了丰富的AI服务,能够为图像处理、音频处理、自然语言处理、视频处理等提供有力的数据支撑。
据王磊介绍,云原生数据湖为AI的应用提供了统一的数据架构,在数据收集、标注、训练、推理等领域都能够发挥更大的作用,而腾讯云凭借全球领先的技术和创新方案,打造了领先的数据湖与AI融合平台,为更多的应用场景提供了智能化的能力。
以腾讯云内容安全智能服务为例,该服务基于云原生数据湖架构,以AI智能审核能力为核心,从接口输入、辅助判断、模型识别、客户策略处理以及人工审核与平台六大维度,为用户提供了完整的内容安全解决方案,让客户一次调用即可完成所有的内容审核工作。在此基础上,腾讯云也不断通过数据湖结合AI的能力赋能客户,在科技战“疫”、OCR识别、智能票财税等应用场景领域发挥了更多的价值和作用。
为企业释放数据价值
当满足了用户对于大数据产品需求之后,对于产品提供者来说,如何让用户快速的用上该产品则成为了下一个问题。
为了让用户更快的建立起数据湖环境,腾讯云原生智能数据湖还打造了两款全新的“开箱即用”数据湖产品——数据湖计算服务(Data Lake Compute,简称:DLC)和数据湖构建DLF(Data Lake Formation,简称:DLF)。
其中,数据湖计算服务DLC服务采用无服务器架构(Serverless)设计,用户无需关注底层架构或维护计算资源,使用标准SQL即可完成对象存储服务(COS)及其他云端数据设施的联合分析计算。借助该服务,用户无需进行传统的数据分层建模,大幅缩减了海量数据分析的准备时间,有效提升了企业数据敏捷度。
不仅如此,腾讯云数据湖构建DLF则提供了数据湖的快速构建,以及与湖上元数据管理服务,能够帮助用户快速高效的构建企业数据湖技术架构,包括统一元数据管理、多源数据入湖、任务编排、权限管理等数据湖构建工具,借助数据湖构建,用户可以极大的提高数据入湖准备的效率,方便的管理散落各处的孤岛数据。
值得注意的是,DLF不仅可以兼容腾讯产品产生的异构数据,它也可以兼容腾讯云之外的异构数据。
数据显示,基于这两款数据湖产品,相比于本地自建大数据集群,数据湖构建时间减少了60%,数据分析计算性能提升35.5%,云端数据湖架构投入使用后可使存算数据量增长75%,配合其他大数据服务,在业务峰值期可以节约30%的硬件资源,以及一半的大数据工程师和运维工程师。
如何保证数据湖的稳定性
对于任何大数据产品而言,其稳定性的重要性是不言而喻的。
对此雷小平对雷锋网表示,腾讯云此次发布的腾讯云原生数据湖产品在内部经历过长期实践和锤炼之后才对外发布的。
以腾讯新闻为例,腾讯新闻拥有千亿级的文章数量,每篇文章各环节数据维度达到几百个,多维度的数据主题导致各个业务环节的数据量线性膨胀,也这给数据分析带了极大的挑战。
为此,基于腾讯云原生数据湖技术架构,在数据采集、数据存储、数据分析的全数据链条上提供了高可靠高可用的弹性数据能力。目前已接入全量文章的索引数据,文章索引达日均30-50亿/100G+ ,支持准实时写入更新,业务数据链路延迟提升至分钟级别,使得算力资源节约超过50%,综合运行成本降低了30%,大数据运维工程师的工作量提升了100%。
“腾讯新闻的数据应用中,既有偏离线的,也有偏实时的,更有偏批量和小部分数据查询的,场景十分的多样化,而腾讯云基于多样化的应用场景,不断对云原生数据湖方案进行孵化和打磨,最终让腾讯云原生数据湖应势而生。”
除此之外,腾讯云正在积极推动数据湖在政务、工业、零售等领域的大规模落地。
目前,腾讯云数据湖体系已服务众多内外部客户,其整体算力弹性资源池已达500万核,存储数据超过100PB,每日分析任务数达1500万,每日实时计算次数超过万亿,能支持上亿维度的数据训练。
显然,作为数智时代的数据处理的新引擎,云原生智能数据湖能够为用户带来更多的可能性。






发表评论 取消回复