雷锋网AI研习社按:作为当下最受欢迎的机器学习方法之一,深度神经网络在很多领域取得了非凡的成绩。但是目前的深度神经网络模型依旧存在很多局限性,例如无法自动地设计网络结构、无法有效地降低网络中的参数冗余度、很难处理嵌入在非欧几里得空间的数据和无标签的数据等等。
分享嘉宾:常建龙,中科院自动化所在读博士。在2015年获得电子科技大学数学与应用数学专业理学学位,之后师从潘春洪和向世明研究员,在中科院自动化所模式识别国家重点实验室攻读博士学位,主要研究方向为基于关系的深度学习,包括自动机器学习、网络压缩、深度图网络、深度无监督学习等等。目前已在IEEE T-PAMI(2篇), NeurIPS和ICCV (Oral) 等机器学习与计算机视觉顶级期刊和会议发表学术论文。
公开课链接:http://www.mooc.ai/open/course/671?=leifeng
分享主题:基于关系的深度学习(Relation-based Deep Learning)
分享提纲:
我们通过建模深度神经网络中变量之间的关系来解决以上问题并提升深度神经网络的性能。
通过考虑样本于样本之间的关系来聚类无标签数据
通过考虑特征与特征之间的关系来处理非欧式空间中的数据
通过考虑神经网络中层与层之间的关系来自动学习网络结构
雷锋网AI研习社将其分享内容整理如下:
大家晚上好,首先来做一个自我介绍,我是中国科学院自动化所在读博士生常建龙,很感谢雷锋网提供的平台,可以在这里跟大家交流我的研究和一些具体的成果。我们今天的主题是基于关系的深度学习,这个词我们自己提出来的,还比较新。现在的深度学习,包括它能处理的一些问题,怎样设计结构等都有一定的局限性,对于这些局限性,我们希望通过建立深度网络或者处理的每一个深度模型中,了解到两两变量之间的关系,从而让深度网络变得更优秀一些。
首先来看看什么叫做关系。关系的范围其实是非常广的,人和人之间的某种关系,比如父子、母子、兄弟姐妹等等;数学中函数集合里的对应关系、包含关系等等。
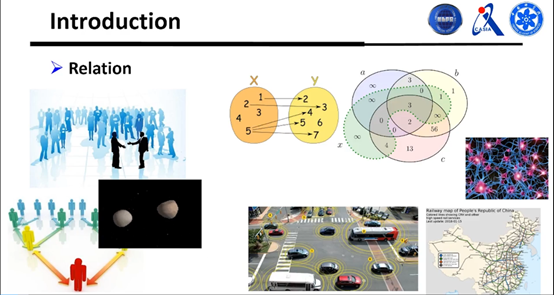
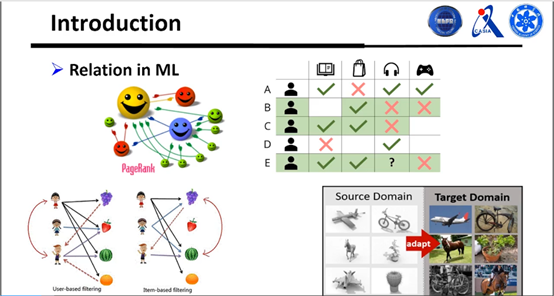
这些关系不仅生活中很常见,在机器学习中也很常见,比如要在Google里搜关键字,就会在关键字和网页之间建立关系,使得搜索了关键字之后网页可以反馈相应的结果。比如迁移学习等等也是建立数据库与数据库之间的关系。
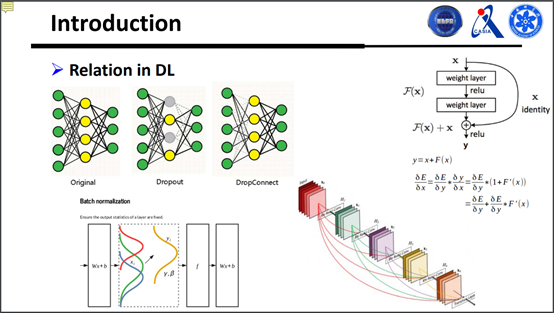
在机器学习深度网络里面也有很多关系,可以说分为很多层面,一种是假如有一个小网络,可以用一些比较常见的算法(Dropout:随机屏蔽一些神经元对性能有益,或者把有些边砍掉能取得比较好的结果)。另外是某些层之间建立了关系之后,能使得训练学习的时候梯度可以更好,对学习也是有益的。另外一个比较火的算法是Batch normalization,它考虑的其实是样本和样本之间的关系。
我们看到这些关系的种类有很多,要怎么很好地在深度网络里面利用这些关系,并使得深度网络能处理更广泛的问题、能有更好的性能等等,这类问题要怎么解决呢?接下来我给大家介绍三种,一种是通过考虑样本和样本之间的关系,使得深度网络模型能很好地处理无标签的数据;另外一类就是暂时的CN或DN这种很难处理的数据,可以建立点跟点之间的关系,让深度网络能够处理这种数据;最后一类就是当下比较火的一个方向,深度网络里面两两层之间到底是以什么样的方式来相连,使它有个比较好的效果。
接下来从三个方面来介绍基于关系的深度学习。第一个就是假如有一堆没标签的样本,希望建立两两样本之间的关系,然后进行聚类,使得神经网络能够直接做无监督学习。
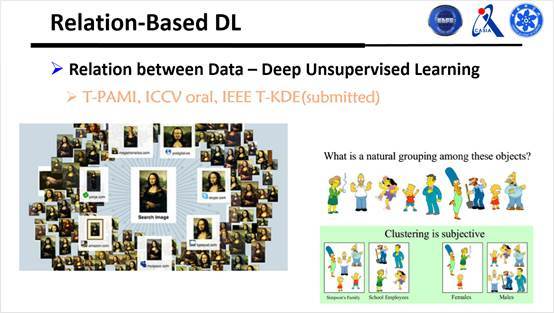
可以先看一下什么叫聚类,它的定义是把一些相似的数据聚集到一起,不相似的不聚集到一起,也就是判断是否属于同一类。
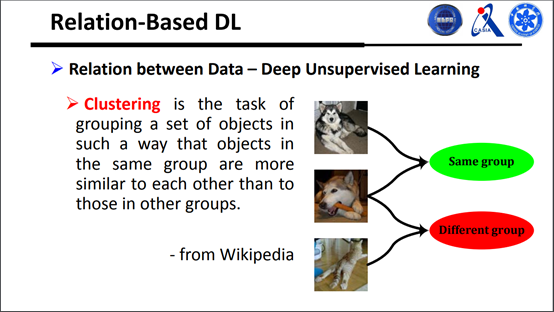
从上面这些简单的定义我们可以对聚类问题做数学上的表达,如下图有g这样一个函数:
但是这个表达有两个问题,第一是通过两两样本之间的关系,只能知道样本是第一类还是第二类,没有办法知道这两个样本到底属于哪一类,另一个问题是在做聚类的时候,不知道两个样本是不是属于同一类。

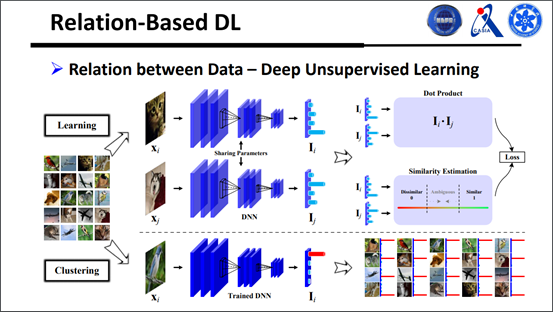
接下来看一下怎么处理这两个问题,我们引入了标签特征的概念,也就是把g函数分解成两个f函数的特征,如图所示:

前面只考虑两两样本的相似性从而判断样本属于哪一类,这里考虑的是怎样得到是否属于同一类的样本。这种做法受启发于课程学习方式,即先学习较简单的样本,再学习复杂样本。对于网络模型而言,怎样叫简单样本呢?如计算出来是1,真实结果是0.9,即为简单样本。

将所谓的关系建模在深度网络里面有什么优势呢?假如给一个约束条件,用传统的机器学习算法去做会很难算,要对输出做一个约束是很困难的事情,但是我们可以建一个比较简单的层,第一个功能就是将所有的值变为正值,第二就是二范数唯一,k为向量,是人为定义的。

公式先放一边,来看一下流程图大家会更容易了解一点。有一堆没标签的样本,但是知道这些样本总共属于多少类,在无标签的数据库中随机选两个样本出来,有一个共享的网络,共享的网络之后有一个输出,一方面计算他们的相似度,另一方面是利用他们的点乘。前面这些都是在学习,后面才开始训练,不必考虑关系,直接给样本进行聚类,最后输出的特征和有监督学习是一样的。
接下来看一下结果,MNIST最终的准确率能达到98%,效果非常好,很难的样本都能聚出来。

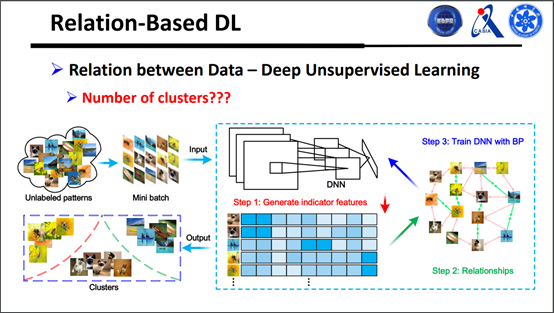
有人问到l的维度怎么确定,提前给定是一种方案,也可以学习一个l出来。那么怎么去学习呢?具体做法也就是对之前的一个扩展,以前的时候只考虑样本和样本之间的关系,但其实可以把样本考虑得更全面一些,相当于把所有样本之间的关系都考虑起来。
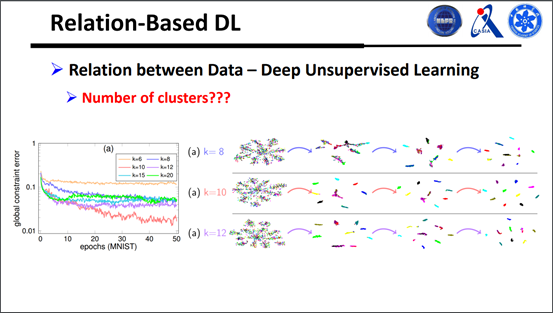
在操作的时候,我们也设置了一些k值的参数,能试试选哪个值损失会最小,细节部分大家可以自己搜索一下。
刚才我们讲的是深度无监督学习,考虑样本和样本之间的关系,没标签也可以用深度网络做处理。下面是属于图网络,以前的图像主要处理的是很标准的结构化数据,数据在很标准的格子空间里面,但是在一些其他场景,比如交通流量、分子、DNA或者三维数据之类的,这些数据嵌入在图的结构上面,每一个点有一个值,这类数据怎么处理呢?怎么把他们的关系建模在深度网络里面?

可以看一下,现在所谓的深度学习主要受益于CN,特别是在图像这些方面,一个很好的特点就是他考虑局部的关系,把局部数据处理好之后,参数可以在任何一个局部用,这对分类是很有效的。
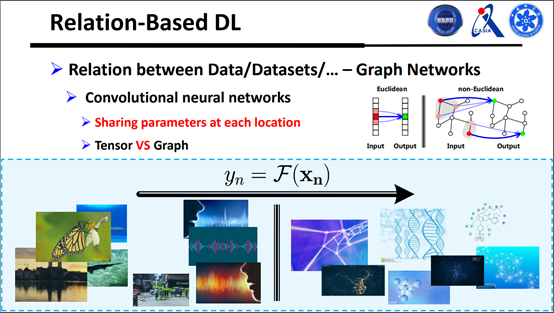
很直观的一个难点在于,确定好的局部数据是有数据关系的。
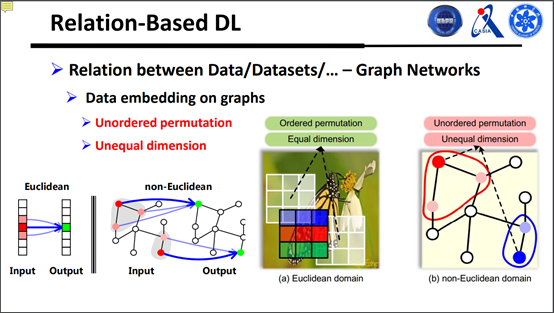
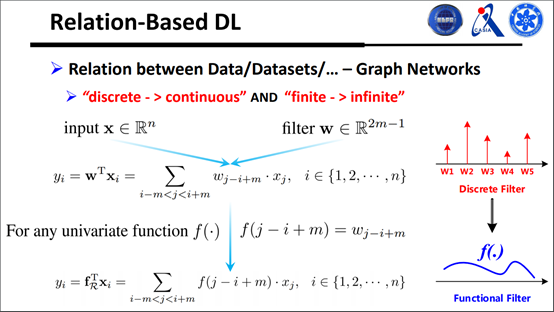
怎样结局这个问题呢?其实是对传统转接做了一个泛化,如图所示:
另外要把局部结构的信息建模到转接盒里面,如下图:

下面来看一下比较简单的转接方式,有两个通道的输入和一个通道的输出,需要两个转接盒,如下图:
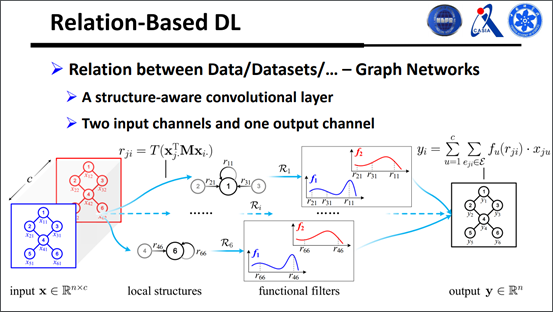
现在一个很重要的问题就是,怎样去学习无穷个转接盒?有人可能会猜到,用傅里叶变换,可以把一个序列函数用奇函数表达出来。我们还对转接方式进行了泛化,写成矩阵乘法的形式,更好地理解这种转接到底是怎么做的,如下图:
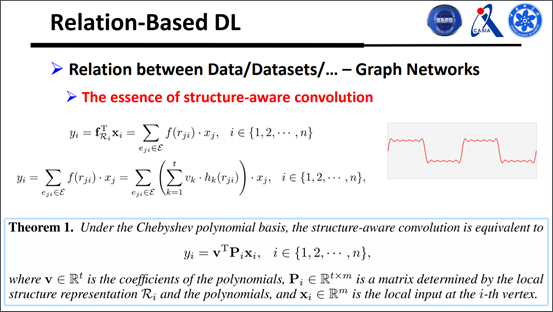
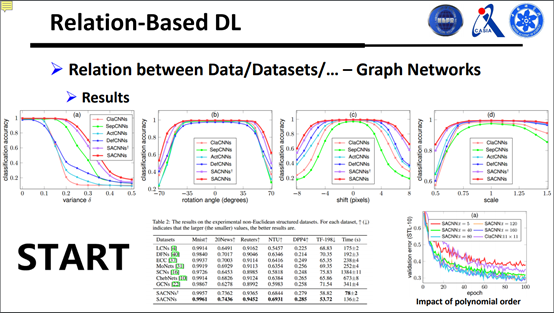
一个很直观的实验是在北京市的交通图上做的,很好地预测北京市的交通流量,另外我们在传统的图像序列也做了实验,如图:
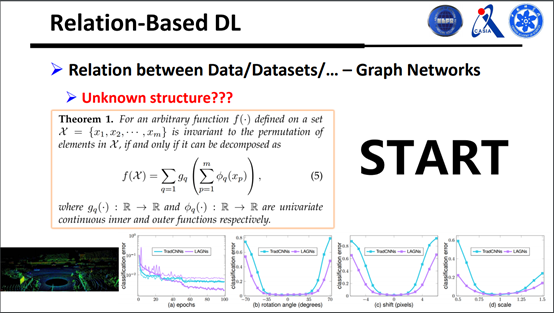
下面我们给出了集合函数的一般形式,所有的集合函数都能用这个式子来表达,如图所示:
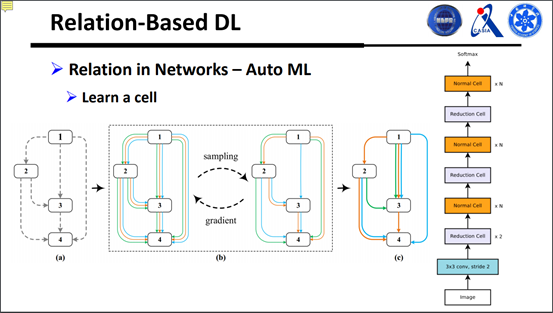
最后一个我们要考虑的是层和层之间的关系,那到底网络连接怎么样才最好呢?按照自动机器学习的意思就是说,可以使得网络结构跟着学习的过程慢慢改变,变得最优,到最后能处理更好的问题。
现在普遍上都是在做这样一件事情,学一个比较小的结构,这个比较小的结构在网络中任何地方去用,乘多少遍,用小的结构,搭成大的结构出来。可以看到网络结构其实是一个比较离散的东西,但是用强化学习去做过程很慢,需要花费很长的时间训练模型,那最好的办法就是用BP算法。
还有就是从连续变到离散之后,怎么传递梯度呢?这是值得考虑的事情。
一方面希望空间大另一方面还希望传递梯度,怎么做呢?如图:

另外我们还做了一些分割上面的实验:
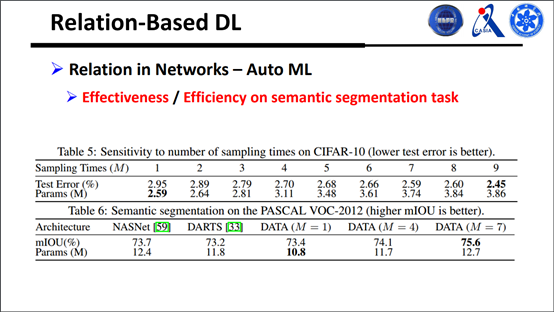
在自动机器学习这方面一个比较好的前景就是,怎样去搜更复杂的任务直接做检测分割等等,这是比较有趣的研究方向。
今天的交流就到这里,谢谢大家。
以上就是本期嘉宾的全部分享内容。更多公开课视频请到雷锋网(公众号:雷锋网) AI 研习社社区(https://ai.yanxishe.com/?=leifeng)观看。关注微信公众号:AI 研习社(okweiwu),可获取最新公开课直播时间预告。






发表评论 取消回复