10月17日的百度世界大会,百度创始人、董事长兼CEO李彦宏官宣文心大模型4.0发布,其中一句话让人印象深刻:文心大模型4.0综合水平与GPT-4相比已经毫不逊色!这么短的时间内,国内大模型是否真就赶上了GPT-4。有媒体针对连着进行了公开的评测,结果显示文心大模型4.0已然在综合能力上可以逼近并比肩 GPT-4,甚至在一些强调文化背景的问题中展现了超越 GPT-4 的态势。
此次测评维度评测整体围绕模型的语言理解、推理、生成、知识、记忆这五个维度展开设计,设计了以下10类评测题:
常识推理题
打败80%人类的中文语言理解题
再上点难度:语言理解+逻辑推理
成年人不擅长的古诗生成题
本土文化考察:90后专属非主流文字识别
弱智吧经典战役
知识问答:四大名著考察
GPT-4最擅长的数学计算
GPT-4最擅长的代码题
测测翻译腔
第一类评测题:常识推理题
首先祭出这个曾经把全体大模型(包括文心一言3.5、通义千问、讯飞星火、ChatGPT等)都干崩了的常识推理Case:
文心大模型4.0

GPT-4

结果显示,文心4.0完胜!几个月过去了,GPT-4还是做不对,但亲测文心4.0成为了目前全世界唯一一个把这个case做对的大模型。
第二类评测题:打败80%人类的中文语言理解题
在语言理解问题上,简单case测试没意义!直接上难度看下两者的表现。
文心大模型4.0

GPT-4
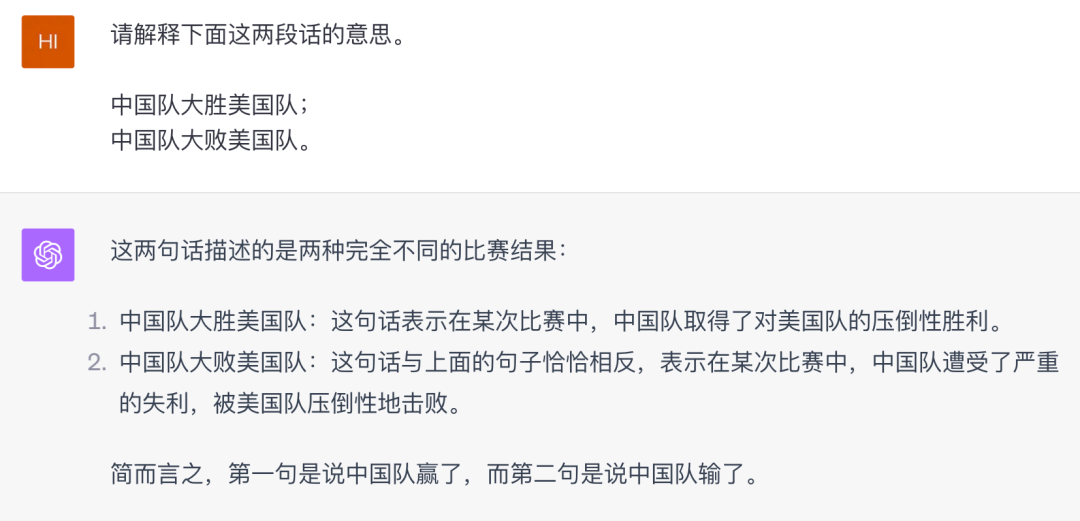
可以看到这一局评测双方表现都差强人意,可以说是打平。尝试一下例子:
文心大模型4.0

GPT-4

本以为这个case两个模型也都要翻车,没想到文心和GPT竟然都做对了。比不出来?那就再来一题!
文心大模型4.0
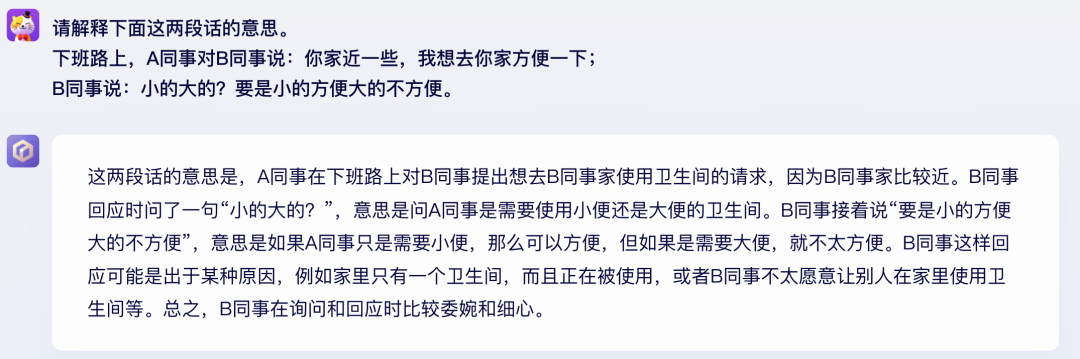
GPT-4

结果竟然又打平了。看来两者的语言理解能力都很强,不分伯仲。
第三类评测题:语言理解+逻辑推理
文心大模型4.0

GPT-4
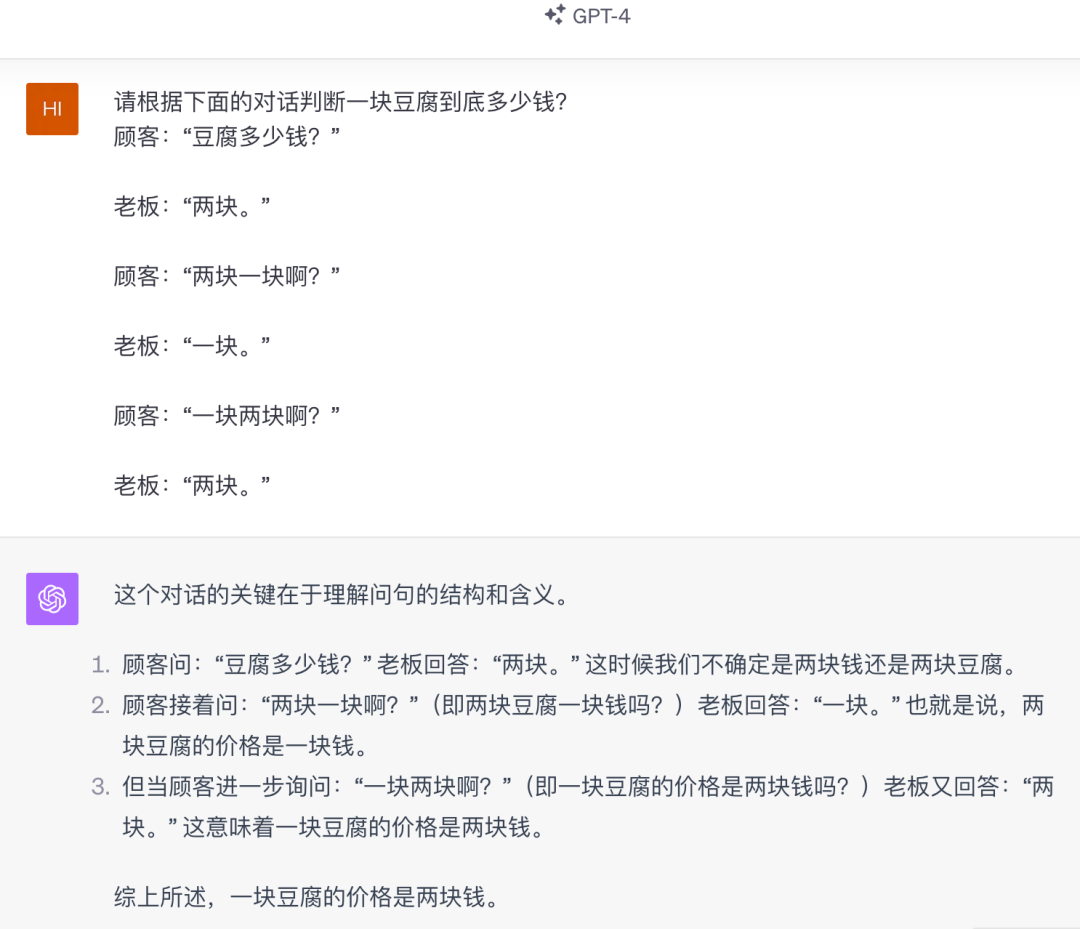
虽然GPT-4和文心4.0答案都对了,但推理过程是错的,这局算打平。
文心大模型4.0

GPT-4

可以看到,文心4.0逐步分析,展现出了清晰的推理逻辑,而 GPT-4 则明显晕了,效果惊艳,文心4.0胜!
第四类评测题:成年人不擅长的古诗生成题
文心大模型4.0

GPT-4

能从结果看出,果然还是百度更懂中文。文心大模型4.0比GPT-4表现更优秀!
第五类评测题:本土文化考察:90后专属非主流文字识别
80、90后一定还记得当年在QQ空间上流行的非主流文字,来,看看你俩有没有刷过QQ空间。
文心大模型4.0
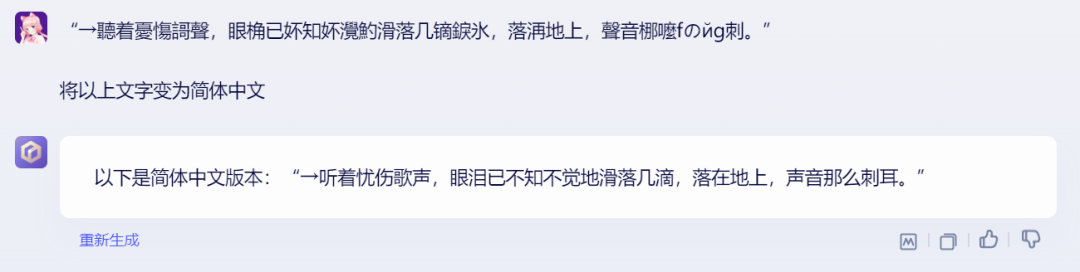
GPT-4
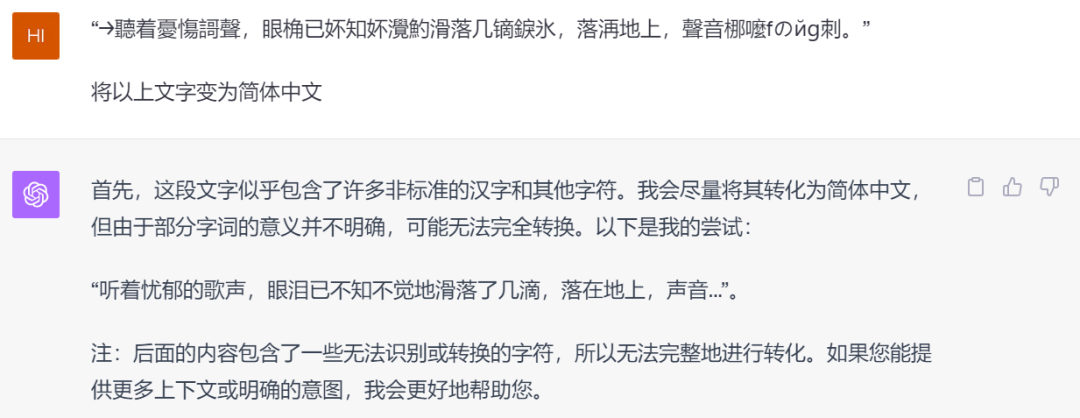
果然,通过这道题,能看出百度是有20年前的互联网记忆的,OpenAI在本土化方面的表现被百度碾压,符合预期!
第六类评测题:弱智吧经典战役
这就必须祭出每逢大模型发布时,媒体的必考题。
文心大模型4.0
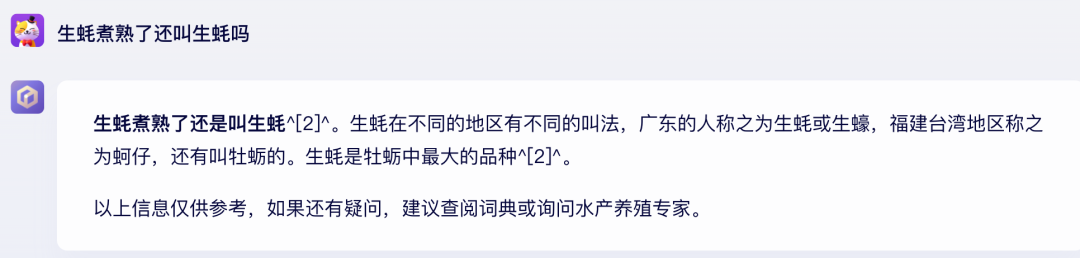
GPT-4
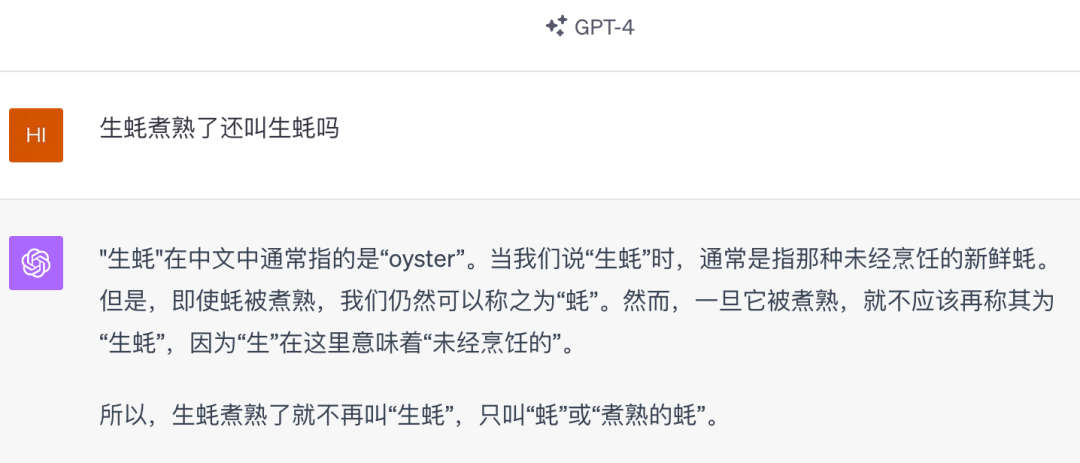
文心4.0完胜!GPT-4太失败了,时隔半年,它还是认为生蚝煮熟后就变成了熟蚝,现在认为煮熟后叫做“蚝”或者“煮熟的蚝”。
第七类评测题:知识问答:四大名著考察
相信大家已经通过上面的评测感受到了文心4.0在中文语言理解等方面对GPT-4形成的碾压。我们接着考察一下两个模型对四大名著的掌握程度。
文心大模型4.0

GPT-4

离大谱!GPT-4不仅真的胡乱编造起来林黛玉倒拔垂杨柳的故事,连孙悟空、观音都搬出来了。
第八类评测题:GPT-4最擅长的数学计算
在我们之前的评测中,GPT-4的数学计算完爆一众国产模型。时隔半年,再来PK一波!
文心大模型4.0
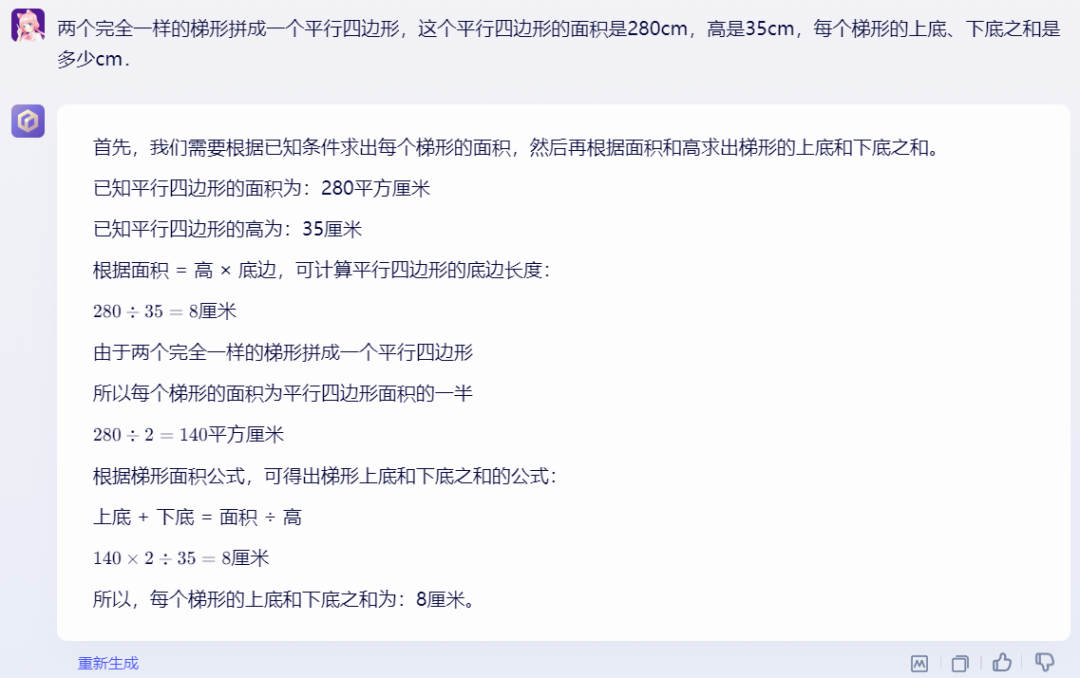
GPT-4

这道题GPT-4竟然答错了,文心大模型4.0在这道数学计算题上赢了GPT-4!当然这只是一个例子,有兴趣的小伙伴可以找更多case进行测试。
第九类评测题:GPT-4最擅长的代码题
直接上NLP算法工程师最熟悉的分词算法,看看NLP大模型对NLP算法的理解能力。
文心大模型4.0



GPT-4
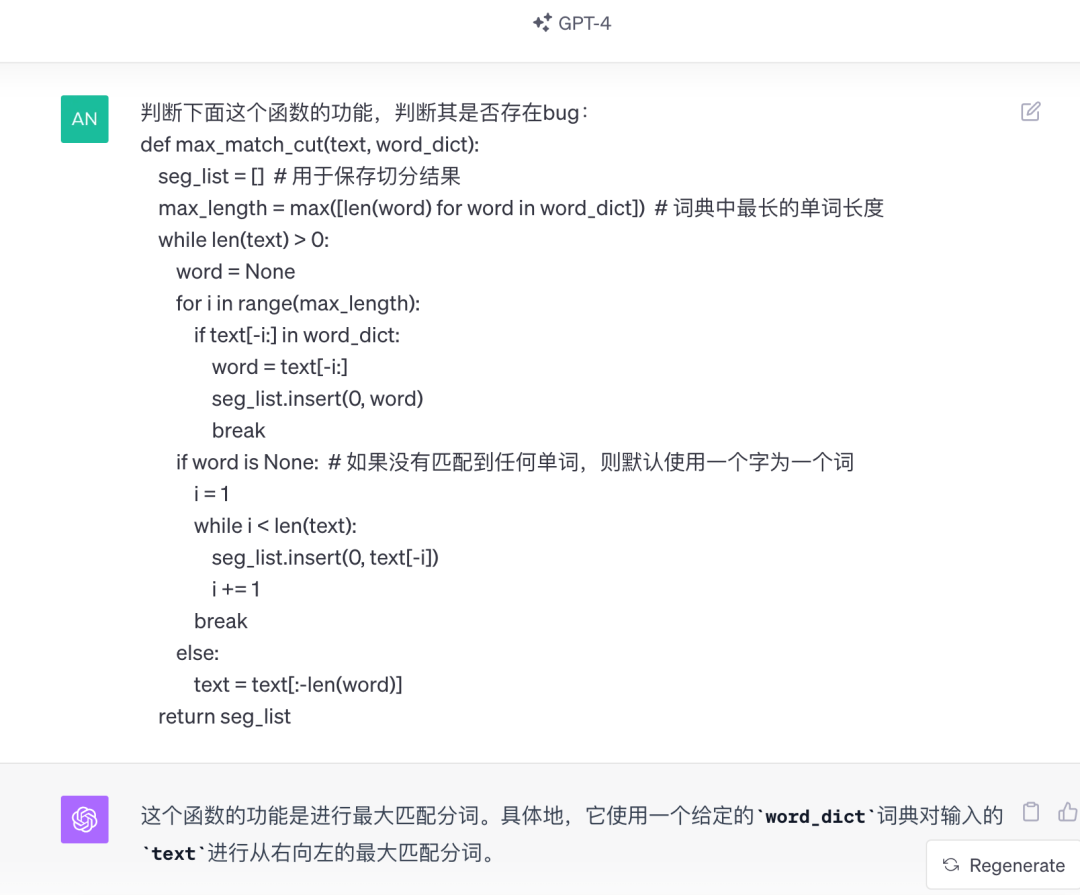

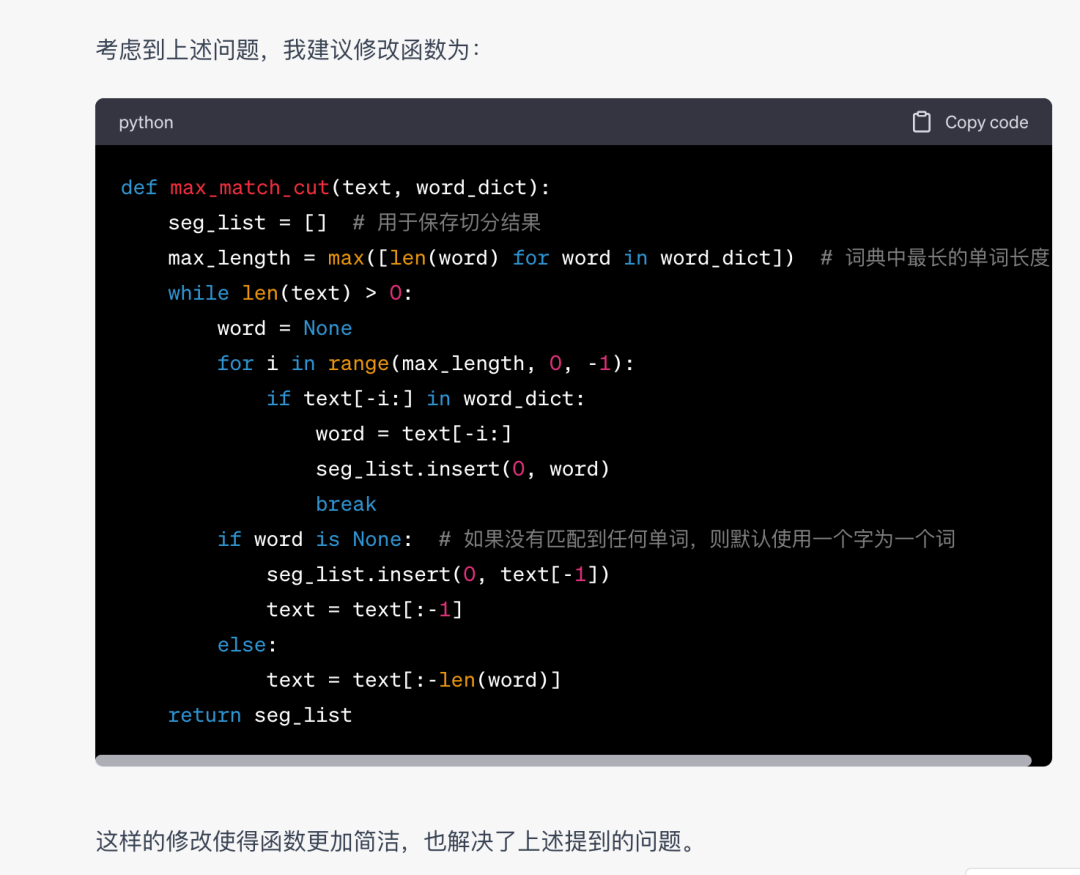
文心大模型4.0的代码能力的确有了不错的提升,本题打平!
第十类评测题:测测翻译腔
做机器翻译容易,但想要翻译出来的内容非常地道,不带翻译腔,其实很难。
文心大模型4.0
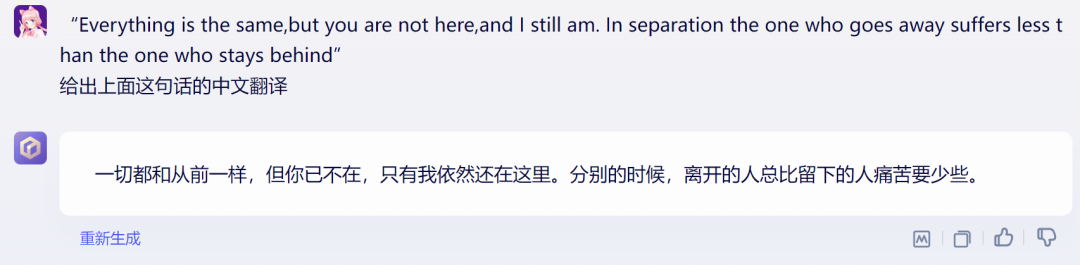
GPT-4
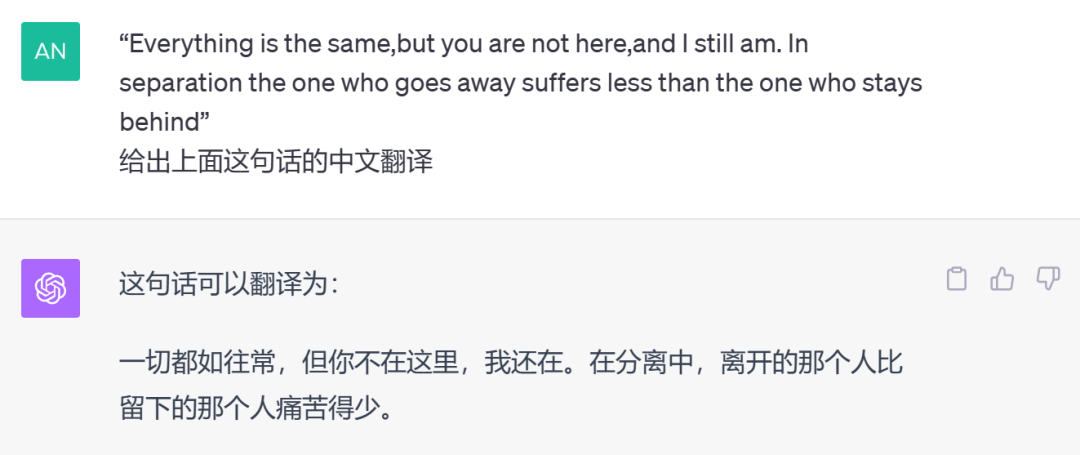 仔细对比下,文心4.0的英翻中的结果翻译腔明显更弱,翻译的更加地道,本题文心4.0胜!
仔细对比下,文心4.0的英翻中的结果翻译腔明显更弱,翻译的更加地道,本题文心4.0胜!
文心大模型4.0

GPT-4

这道题,文心大模型4.0竟然翻译成了古诗,足以看出在中文上的领先优势!
由于case有限,尽管从这不到20个case中,看起来文心大模型4.0效果比GPT-4效果好很多,但实际上由于测试类型覆盖不够全,因此不能得出置信的文心大模型4.0比GPT-4强的结论,仅能作为一个对两个大模型能力特色的感性认知。整体上,可以看出文心大模型4.0的表现非常超出预期,相比3.5版本的提升实在是太大了。
一直以来,国内外无数大模型测评榜单来来去去回回,其中哪怕是在中文能力之上,始终位居榜首纹丝不动的仍然是目前世界上最先进的大模型——GPT-4。而伴随着文心大模型4.0的发布,经过测评后,可以给出的答案是:
“文心大模型4.0综合水平与GPT-4相比确实已经毫不逊色!”
通过上面从理解、生成、逻辑、记忆这四大能力出发并且不断切换不同展示能力的视角与问题,可以看到文心大模型4.0已然在综合能力上可以逼近并比肩 GPT-4,甚至在一些强调文化背景的问题中展现了超越 GPT-4 的态势。文心大模型在4.0时代综合能力的进化,是为未来一个智能时代的到来奠基。
雷峰网(公众号:雷峰网)






发表评论 取消回复