雷锋网 AI 科技评论按:本文作者赵通,是来自美国圣母大学计算机系 DM2 实验室的博士生。本文是他为雷锋网 AI 科技评论撰写的基于 BigData 录用论文《Actionable Objective Optimization for Suspicious Behavior Detection on Large Bipartite Graphs》的独家解读稿件,未经许可不得转载。
前言
恶行是可怕的。章莹颖绑架失踪案过去了 500 余天,还没有实质进展。2017 年 4 月,未满 27 岁的北大硕士毕业生章莹颖作为访问学者前往美国伊利诺伊大学香槟分校交流学习。6 月 9 日下午 2 点,章乘坐公交赴校外公寓签约,在转站等车时,不慎上了一辆陌生男子的黑色轿车,之后再也没有人见过她。当晚其好友与教授报警,一直到 6 月 30 日,美国警方拘捕一名白人男子,称章可能已死亡。7 月 12 日,联邦大陪审团正式起诉嫌疑人,到目前为止,此案仍在法庭受理当中。类似的情形在国内也时有发生,「滴滴顺风车」命案便是血淋淋的悲剧。每每出现在新闻标题里的「又一女孩」或是「三个月内第二名乘客」这些字眼,都让人纳闷,究竟是什么让这类事件一而再、再而三地发生。恶行不只出现在现实生活中,在网络中也无处不在,如在淘宝和 eBay 上就存在买家「霸凌」卖家的行为:买家只需购买卖家的一件便宜商品,即获得给商品评价、打分的权利。买家如若无视商品质量,打出极低的分数,卖家的平均分数就会降低,而平台推荐系统往往根据评分排行,评分稍微降低一点,都会导致卖家在和其余商家竞争时无法出现在被推荐的第一页,从而失去生意,最终倒闭。因此买家利用卖家的弱点,可以索要折扣乃至现金等,这就是「霸凌买家」的由来。
引出问题
在关注各种案件的同时,我们不得不思考:当我们面临即将到来的恶行时,我们是否能够提前防范恶性事件的发生?越是思考,越是让人不寒而栗——比起生活上的孤零零,更可怕的是信息的贫瘠与环境的复杂。
父母亲的一句「注意安全」遇上了「签订租约」、「错过公交」、「迟到误点」、「校内路边」、「黑色轿车」、「白人男子」、「邀请上车」等陌生环境下的复杂情景,都显得苍白无力。受害人的判断力迅速被「准时准点」、「诚实守信」、「文明发达」、「乐于助人」冲垮。如果这些状况发生在她的家乡福建省南平市,想必她会冷静很多:太多的事故、故事以及对周遭的了解让她拥有足够多的信息去面对复杂环境。试想,如果莹颖曾看过伊利诺伊大学校园犯罪地图、听过一些危险事件的报道,在内心里构建起一座防范恶行的「防火墙」,她也许会在「签约误点」的情况下对「上陌生人的黑色轿车」这一选择要多加斟酌,从而避免这一悲剧的发生。一句简单的「注意安全」,信息量真的是太少了。
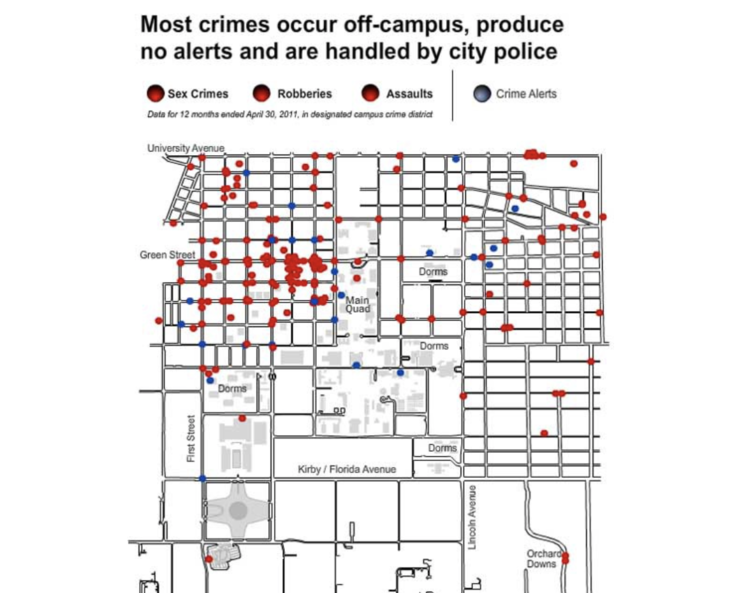
图一:来自 CampusCrime.net:性犯罪、抢劫等恶性事件的校园分布
虽然政府与各方平台已经非常努力地给人民与用户提供最优质、最安全的服务,他们却很难提前对恶行做出有效的防范。因为将好人误判为坏人的代价是巨大的。试想,当重要邮件被误扔进了垃圾箱,当一批正常的淘宝用户被封号,当警方误逮捕「可疑人员」,这些都必会导致服务劣质化、抱怨四起、平台收益受损、责任难以承担等诸多负面影响。这就是为什么政府与平台虽坐拥计算与大数据资源,却显得反应迟钝、畏首畏尾。不过在责难平台的同时,用户自身也忽略了安全意识的建立,忘记了自己才是最有执行力去说「不」的人。
我们的想法
当我们观察到平台与用户之间存在着这条很长很深的信息鸿沟时,圣母大学计算机系数据决策实验室(DM2 Lab, University of Notre Dame)尝试使用一种新的思路去弥补这一鸿沟。为了统一称谓,我们称发出行为的人为「主动方」,包括搭讪者、粉丝、司机等;接受行为的人为「被动方」,包括被搭讪者、被关注者、乘客等,其中「主动方」存在产生恶性行为的可能。传统的恶行检测算法(suspicious behavior detection)往往以「主动方是否为攻击者」的标签作为优化的变量,从而使得平台可以对预测为正例者进行人工调查、再做出决策,调查过程费时费力。DM2 提出,让「被动方」根据对「主动方」的特征或者行为历史的观察形成防范意识、选择防御等级,例如女性乘客可以根据司机年龄性别、驾龄、过往评分和评价等信息进行筛选。这里就存在一个妥协的问题:防御等级过高,则得到服务的范围和及时性会降低;防御等级过低,则安全又难以得到保证。用户个体是很难选择合理等级的,而平台却拥有海量数据和智能算法,可以为用户推荐合适的防御等级并估计选取后的结果,让用户自行选择。这样用户拥有安全意识、平台也可以「推卸」一部分责任,信息鸿沟得以弥补,恶意行为的防范变得可操作、可执行。
事实上,由用户个体来防范恶行的思路并不是第一次出现,如淘宝就有插件可以用来屏蔽差评师(好评率低于一定百分比的买家)。

图二:差评师拦截插件
然而,这看似安全的作法,却也有不小的负面影响。当卖家「防御等级」过高时,很多诚实却打过低分的买家无法购买商品,导致卖家损失订单。如下图中的例子:
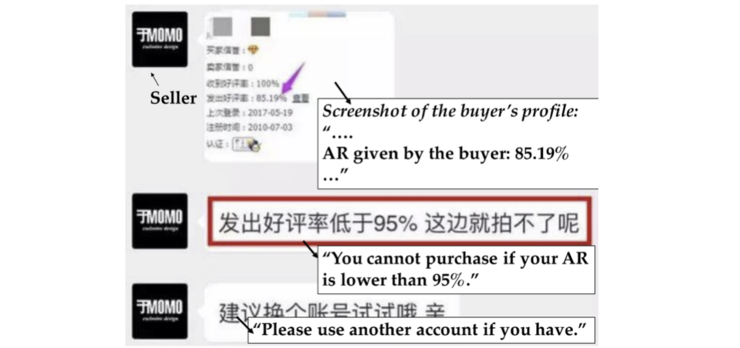
图三:好评率为 85% 的诚实买家无法购买此家店的商品
DM2 所提出的 Actionable Objective Optimization (AOO) 算法将被动方的防御等级作为优化变量,将整体的安全系数和服务质量作为优化目标,在最常见的二部图 (bipartite graph) 形式的行为数据上,取得了很好的效果。该算法已被 IEEE BigData 2018 (http://cci.drexel.edu/bigdata/bigdata2018/) 接收为长文。第一作者为圣母大学一年级博士生赵通,指导老师是助理教授蒋朦。
方法论
很多关于恶性防范算法的文献都发现,在用二部图表示的行为数据上,异常密集的二部子图(dense bipartite core)十分可疑。当我们用矩阵 A 来表示这个二部图时,原图中密集的子图就变成了矩阵 A 之中密集的子矩阵。现有的传统方法大多是通过各种方式最终给每一个主动方打上一个可疑程度的分数,这些分数放在一起就是一个长度为主动方总数的向量 p。然后,再去优化那些较可疑的主动方所形成的子矩阵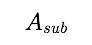 的密度 J ,所以目标方程可以表达为:
的密度 J ,所以目标方程可以表达为:
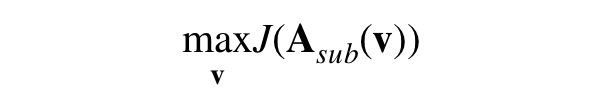
与传统地去优化主动方可疑程度这一变量的方法不同,AOO 的思路在于优化被动方的防御等级,使得最终被屏蔽掉的行为成为一个密度远大于正常数据的子矩阵。AOO 要去给每个被动方一个针对主动方的某个特性的防御等级或是门槛,它们放在一起则是一个长度为被动方总数的向量 v。当主动方 i 的特性不能满足被动方 j 的门槛时,j 便可以屏蔽掉与 i 的这次行为。那么优化这个被屏蔽掉的行文所形成的子矩阵的目标方程就是:
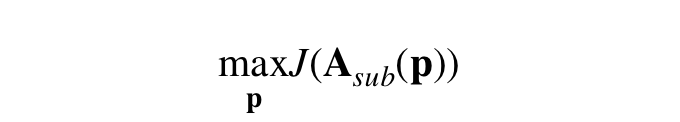
这两个公式看似相似,实则大不相同。因为他们完全从主动方和被动方两个角度切入了这个研究问题。并且实际上只有被动方才是可以提前防范恶意行为的执行者。
在网购平台中,主动方(买家)的特征可以为这个买家的历史平均评分。被动方(卖家)的防御等级自然如同上文中提到的淘宝插件,是一个可以在此店购买的商品的买家平均评分门槛。如此以来,当买家的历史平均评分低于卖家的门槛时,这个买家就无法在这家店购物。
当我们给定一个数据集后,通过给每个卖家生成一个门槛而生成一个长度为卖家数量的相当 v 之后,我们便可以利用 v 和 A 来计算出一个 0/1 矩阵 B。对于 B 中的每一个值 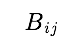 ,若卖家 j 会屏蔽掉与买家 ‘i 的交易,的值就是 1,如不会屏蔽则为 0。当然,只有本来就有交易的买家与卖家才会被考虑,所以我们用矩阵 I 来表示交易存在与否,即如果卖家 j 与买家 i 之间本来就没有交易,
,若卖家 j 会屏蔽掉与买家 ‘i 的交易,的值就是 1,如不会屏蔽则为 0。当然,只有本来就有交易的买家与卖家才会被考虑,所以我们用矩阵 I 来表示交易存在与否,即如果卖家 j 与买家 i 之间本来就没有交易,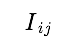 自然是 0,反之则为 1。
自然是 0,反之则为 1。
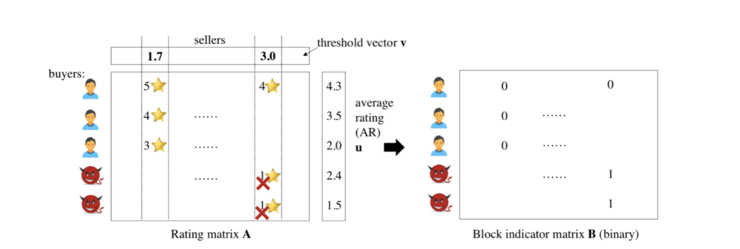
图四:简单的评分数据样例演示矩阵 A 与 B
如果用数学公式来表达的话。我们首先可以方便地求得表示每个买家历史平均打分的向量 u:(m 为买家的数量,n 为卖家的数量)
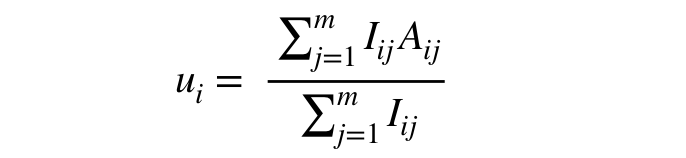
然后我们便可求得矩阵 B:
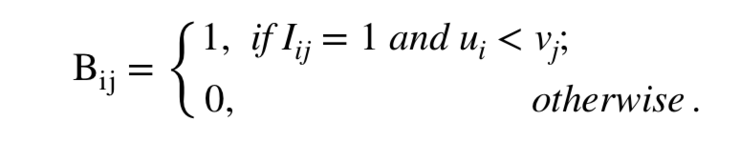
接下来,我们只需要找出矩阵 B 中,被屏蔽了一定次数( )的买家以及屏蔽了一定数量(
)的买家以及屏蔽了一定数量( )买家的卖家。我们通过两个 0/1 向量
)买家的卖家。我们通过两个 0/1 向量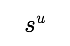 和
和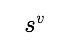 来指示相应的买家和卖家是否为霸凌者与被霸凌者:
来指示相应的买家和卖家是否为霸凌者与被霸凌者:
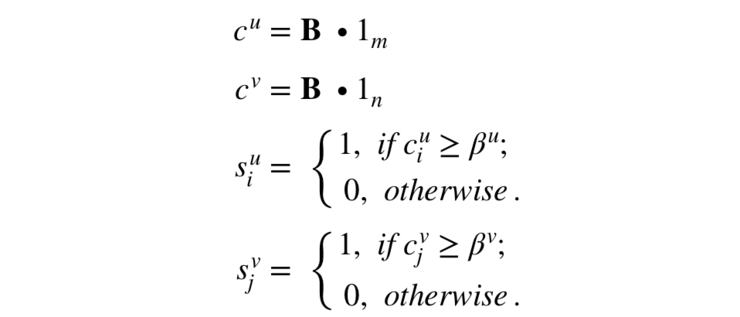
这些买家与卖家形成一个子矩阵,我们的目标是最大化这个子矩阵的密度。在求它的密度之前我们首先需要求出这个子矩阵的大小(长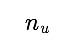 宽
宽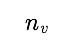 )与他的内容之和(e):
)与他的内容之和(e):
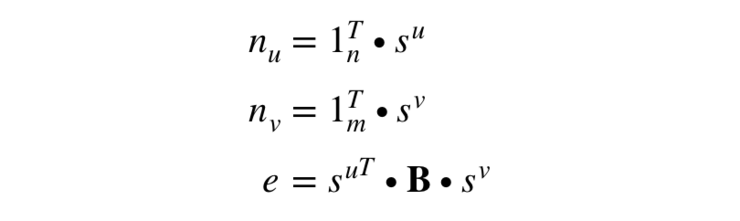
所以我们的目标方程可以表示为:
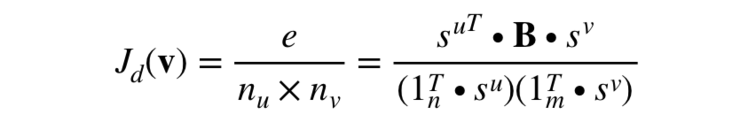
通过对带有矩阵变量的函数求偏导,可以求得该目标方程关于 v 的一阶导数。由于我们的目标方程较为复杂,我们首先对其进行简单的分解:
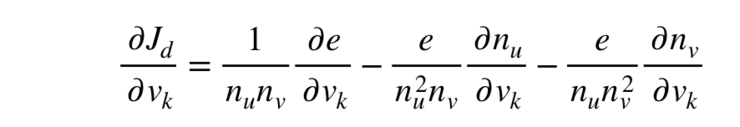
这样我们只需要求出这个式子中的三个重要的偏导便可得出最终目标方程的导数。这三个偏导为:
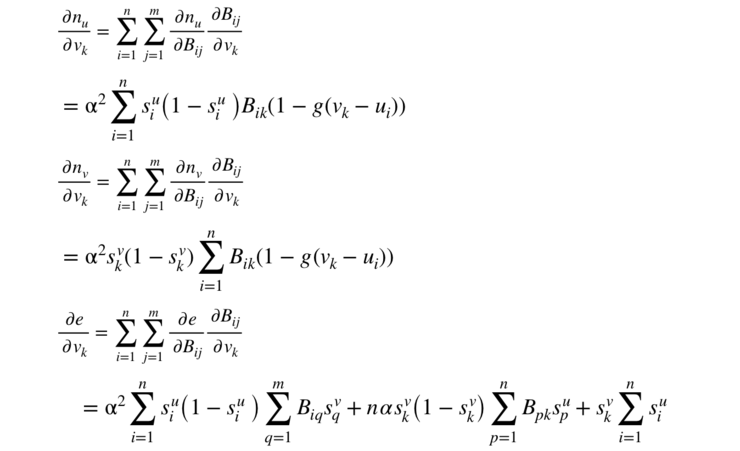
(其中为 sigmoid 方程,为 sigmoid 方程的参数,具体推导过程请参照原论文。)
有了目标方程关于 v 的导数后,我们只需通过梯度下降法便可优化出一个优秀的向量 v,而其中所包含的正是每个卖家所需要设置的门槛。通过利用整个平台的大数据所优化出的每个卖家的门槛,自然会比卖家自己凭借少量经验所设置的要有效得多,而且不会「误伤」太多诚实买家从而更多地保留了销售额。
实验分析
在实验中,这篇论文同时用了人造数据以及真实数据来佐证其效果。文中的人造数据设定十份复杂以求尽量涵盖多种现实中可能出现的情况。在人造数据中,本文所提出的 AOO 与多个最为流行的异常行为检测算法和欺诈行为检测算法做了对比,并取得了相同或更优秀的结果。
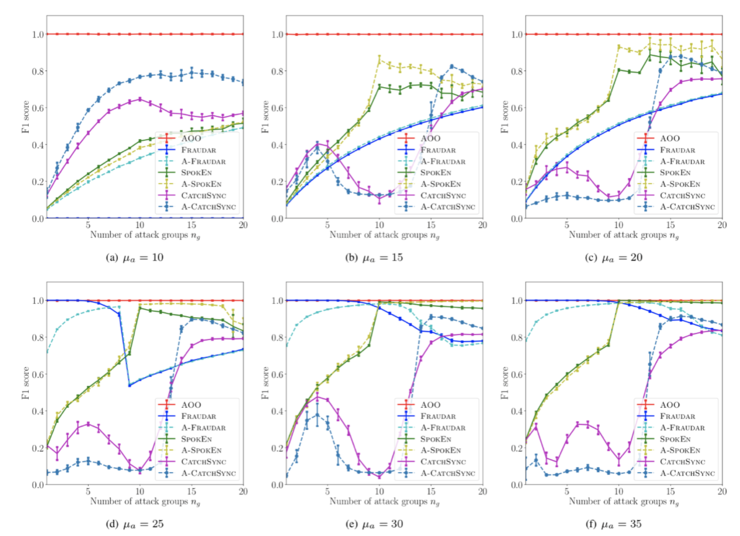
图五:当有一组或多组霸凌买家时,方法在霸凌买家做出不同数量的差评时的效果。与流行的几个异常行为检测算法(KDD'14, KDD'16)作比较,AOO 的效果几近完美。
在真实数据的实验中,由于并没有任何平台公开过带有是否为霸凌买家的标签的数据,这篇论文采用了美国亚马逊(Amazon.com)的商品评论数据,并对 AOO 所检测出的疑似恶意产品评论与其他的买家所做出的产品评论做了对比。结果十分有趣:

图六:美国亚马逊商品评论词云
在图六中,图六(a)所显示的是整个数据集中所有商品评论的用词频率的词云,从中可以看出整体数据集是倾向于好评的,用户也有用了很多非常正面的词汇比如:good, love, like, great 等。图六(b)所显示的是 AOO 所检测出的可疑差评的词云,图六(c)所显示的是 AOO 认为并不可疑的评论中的差评的词云。从图中可以看出,在同样都是差评,同样都出现了高频率的 bad, boring 等负面词汇的情况下:图六(c)中的词汇更为温和,如 disappointing, problem, unfortunately;而图六(b)中的词汇却很暴戾甚至带有侮辱性,如 terrible, stupid, horrible, hell。虽然数据本身并无官方标签来验证 AOO 所得出的结果是否正确,但是数据中的评论词汇说明了这些用户带有更多的恶意。
小结
在本文中,我们简单地介绍了 BigData2018 这篇防范恶意行为的论文。这篇论文新颖地提出了从用户、被害者的角度去提前防范恶意行为的思路。文中的 AOO 模型虽然已经在评分的数据中取得了不错的效果,但是要想让人们在多种复杂的生活环境中去防范各种各样的恶意行为,还需学者们对这一领域进行更加深入的研究。相信不久之后会有越来越多的从用户的角度关注问题的相关文章出现,更多以人为本的研究课题被提出。让我们拭目以待!






发表评论 取消回复